08 決策樹與隨機森林
08 決策樹與隨機森林
決策樹之信息論基礎
認識決策樹
-
來源: 決策樹的思想來源非常樸素,程序設計中的條件分支結構就是if – then 結構,最早的決策樹就是利用這類結構分割數據的一種分類學習方法。
-
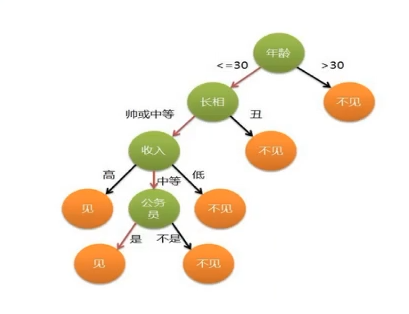
舉例:是否見相親對象
信息的度量和作用
- 克勞德 .艾爾伍德 .香農:信息論創始人,密西根大學學士,麻省理工學院博士。 1948年發表了划時代論文 – 通信的數學原理,奠定了現代信息論的基礎。
-
信息的單位: 比特 (bit)
- 舉例: 以32支球隊爭奪世界杯冠軍
-
如果不知道任何球隊的信息,每支球隊得冠概率相等。
以二分法預測,最少需要使用5次才能預測到準確結果。 5 = log32 (以2為底)
5 = -(1/32log1/32 + 1/32log1/32 + ……) -
開放一些信息,則小於5bit, 如1/6 德國,1/6 巴西, 1/10 中國
5 > -(1/6log1/4 + 1/6log1/4 + ….)
- 信息熵:
- “誰是世界杯冠軍”的信息量應該比5 bit少, 它的準確信息量應該是:
- H = -(p1logp1 + p2logp2 + p3logp3 +……p32logp32 ) Pi 為第i支球隊獲勝的概率
- H 的專業術語就是信息熵,單位為比特
決策樹的劃分以及案例
信息增益
-
定義: 特徵A對訓練數據集D的信息增益g(D,A), 定義為集合D的信息熵H(D)與特徵A給定條件下D的信息條件熵H(D|A) 之差,即:
g(D,A) = H(D) – H(D | A)
注: 信息增益表示得知特徵 X 的信息而使得類 Y的信息的不確定性減少的程度。 -
以不同特徵下的信貸成功率為例
- H(D) = -(9/15log(9/15) + 6/15log(6/15)) = 0.971 # 以類別進行判斷,只有是否兩種類別
- gD,年紀) = H(D) – H(D’|年紀) = 0.971 – [1/3H(青年)+ 1/3H(中年)+ 1/3H(老年)] # 三種年紀對應的目標值均佔1/3
– H(青年) = -(2/5log(2/5) + 3/5log(3/5)) # 青年類型中,類別的目標值特徵為(2/5, 3/5)
– H(中年) = -(2/5log(2/5) + 3/5log(3/5))
– H(老年) = -(4/5log(2/5) + 1/5log(3/5))
令A1, A2, A3, A4 分別表示年齡,有工作,有房子和信貸情況4個特徵,則對應的信息增益為:
g(D,A1) = H(D) – H(D|A1)
其中,g(D,A2) = 0.324 , g(D,A3) = 0.420 , g(D,A4) = 0.363
相比而言,A3特徵(有房子)的信息增益最大,為最有用特徵。
所以決策樹的實際劃分為:
常見決策樹使用的算法
- ID3
- 信息增益,最大原則
- C4.5
- 信息增益比最大原則 (信息增益占原始信息量的比值)
- CART
- 回歸樹: 平方誤差最小
- 分類樹: 基尼係數最小原則 (劃分的細緻),sklearn默認的劃分原則
Sklearn決策樹API
- sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None, random_state=None)
- criterion (標準): 默認基尼係數,也可以選用信息增益的熵‘entropy’
- max_depth: 樹的深度大小
- random_state: 隨機數種子
- 決策樹結構
sklearn.tree.export_graphviz() 導出DOT文件格式
- estimator: 估算器
- out_file = “tree.dot” 導出路徑
- feature_name = [,] 決策樹特徵名
決策樹預測泰坦尼克號案例
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
"""
泰坦尼克數據描述事故后乘客的生存狀態,該數據集包括了很多自建旅客名單,提取的數據集中的特徵包括:
票的類別,存貨,等級,年齡,登錄,目的地,房間,票,船,性別。
乘坐等級(1,2,3)是社會經濟階層的代表,其中age數據存在缺失。
"""
def decision():
"""
決策樹對泰坦尼克號進行預測生死
:return: None
"""
# 1.獲取數據
titan = pd.read_csv('./titanic_train.csv')
# 2.處理數據,找出特徵值和目標值
x = titan[['Pclass', 'Age', 'Sex']]
y = titan[['Survived']]
# print(x)
# 缺失值處理 (使用平均值填充)
x['Age'].fillna(x['Age'].mean(), inplace=True)
print(x)
# 3.分割數據集到訓練集和測試集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 4. 進行處理(特徵工程) 特徵,類別 --> one_hot編碼
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient='records'))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient='records')) # 默認一行一行轉換成字典
print(x_train)
# 5. 用決策樹進行預測
dec = DecisionTreeClassifier()
dec.fit(x_train, y_train)
# 預測準確率
print("預測的準確率:", dec.score(x_test, y_test))
# 導出決策樹
export_graphviz(dec, out_file='./tree.dot', feature_names=['Pclass', 'Age', 'Sex'])
return None
if __name__ == '__main__':
decision()隨機森林
集成學習方法
- 定義:集成學習通過建立幾個模型組合,來解決單一預測問題。其工作原理是生成多個分類器 / 模型,各組獨立地學習和作出預測。這些預測最後結合成單預測,因此優於任何一個單分類的租出預測。
隨機森林
-
定義:在機器學習中,隨機森林是一個包含多個決策樹的分類器,並且其輸出的類別是由個別樹輸出的類別的眾數而定。
例如: 訓練了5棵樹,其中4棵樹的結果是True, 1棵樹為False, 那麼最終的結果就是True. (投票) -
問題: 如果每棵樹使用相同的特徵,相同的分類器,參數也相同,建立的每棵樹不就是相同的么?
隨機森林建立多個決策樹的過程:
單個樹的建立:(N個樣本,M個特徵)
- 隨機在N個樣本中選擇一個樣本,重複N次, 樣本有可能重複
- 隨機在M個特徵當中選出m個特徵 m << M
- 建立10棵決策樹,樣本,特徵大多不一樣 隨機有放回的抽樣 (bootstrap抽樣)
為什麼要隨機抽樣訓練集?
如果不隨機抽樣,每棵樹的訓練集都一樣,那麼最終訓練處的樹分類結果也是完全一樣的
為什麼要有放回的抽樣?
如果不是有放回的抽樣,那麼每棵樹的訓練樣本都是不同的,都是沒有交集的,這樣的每棵樹都是“有偏的”,“片面的”。即,每棵樹訓練出來都是有很大的差異,而隨機森鈴最後分類取決於多棵樹(弱分類器)的投票表決。
隨機森林 API
- 分類器:sklearn.ensemble.RandomForestClassifier
- n_estimators:integer(整數),option, default=10 (森林里數目的數量)
- criteria: string (default =’gini’) 分割特徵的測量方法
- max_depth 樹的最大深度
- max_feature = ‘auto’ 每個決策樹的最大特徵數量
- bootstrap: default = True 是否放回抽樣
隨機森林的優點
- 在當前的所有算法中,具有極好的準確率
- 能有有效地運行在大數據集上 (樣本,特徵)
- 能夠處理具有高維特徵的輸入樣本,不需要降維
- 能夠評估各個特徵在分類問題上的重要性
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!