阿里如何將“高峰前擴容、高峰后縮容”的夢想照進現實?

阿里妹導讀:面對數據庫實例和存儲規模的不斷增長,大促成本、調度效率等難題,2017 年阿里就開始小範圍應用新型技術架構——“存儲計算分離”,以更低成本支撐彈性大促。
2018 年,我們實現了全單元規模化部署存儲計算分離。不過在此之前,各個業務都需要根據自身業務特性進行大量優化。數據庫領域更是如此,而且要求更加苛刻,難度更大。今天,來自阿里存儲技術事業部的高級技術專家呂健,將詳細解讀在 2018 雙 11 大促中,阿里如何打破存儲與計算之間的技術壁壘,從而實現無需搬動數據即可靈活彈性擴容的技術突破。
一、2017 年我們做了什麼?
記得早在 2017 年的時候,王堅博士就曾召大家就關於“IDC As a Computer”是否能做到,進行過激烈的討論。而要做到此,必須要實現存儲計算分離,分離後由調度對計算和存儲資源進行獨立自由調度。而在實現存儲計算分離的所有業務中,數據庫是最難的。因為數據庫對I/O的時延和穩定性有着極高的要求。但是從業界來看,存儲計算分離又是一個未來的技術趨勢,因為像 Google spanner 以及 Aurora 都已經實現了。
所以 2017 年,我們抱着堅定的信念,去實現數據庫的存儲計算分離。事實上,2017 年我們做到了,基於盤古和 AliDFS (ceph 分支) ,在張北單元存儲計算分離承擔 10% 的交易量。2017 年是數據庫實現存儲計算分離的元年,為 2018 年大規模實現存儲計算分離打下了堅實的基礎。
二、2018 技術突破?
如果說 2017 年是數據庫實現存儲計算分離的突破之年的話,那麼 2018 年就是追求極致性能的一年,也是由試驗走向大規模部署的一年,其技術的挑戰可想而知。在 2017 年的基礎上,2018 年的挑戰更為巨大,需要讓存儲計算分離更加的高性能、普適、通用以及簡單。
2018 年,為了使得在存儲計算分離下數據庫的I/O達到最高性能和吞吐,我們自研了用戶態集群文件系統 DADI DBFS。我們通過將技術沉澱到 DADI DBFS 用戶態集群文件上,賦能集團數據庫交易全單元規模化存儲計算分離。那麼成為存儲中台級產品,DBFS 又做了那些技術上的創新呢?
2. 1 用戶態技術
2. 1.1 “ZERO” copy
我們直接通過用戶態,旁路 kernel,實現I/O路徑的“Zero”copy。避免了核內核外的 copy,使得吞吐和性能都有了非常大的提高。
過去使用 kernel 態時,會有兩次數據 copy,一次由業務的用戶態進程 copy 數據到核內,一次由核內 copy 到用戶態網絡轉發進程。這兩次 copy 會影響整體吞吐和時延。
切到純用戶態之後,我們使用 polling 模型進行I/O request 請求的發送。另外對於 polling mode 下 CPU 的消耗,我們使用了 adaptive sleep 技術,使得空閑時,不會浪費 core 資源。
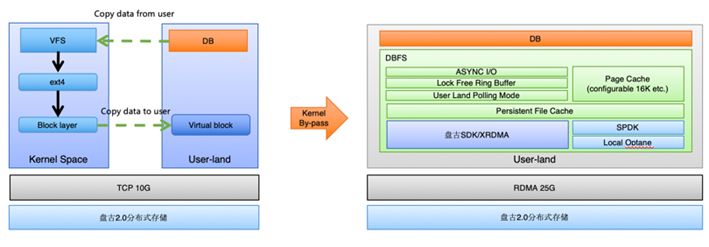
2. 1.2 RDMA
另外,DBFS 結合 RDMA 技術與盤古存儲直接進行數據交換,達到接近於本地 SSD 的時延和更高的吞吐,從而使得今年跨網絡的極低時延I/O成為可能,為大規模存儲計算分離打下了堅強的基礎。今年集團參加大促的 RDMA 集群,可以說是在規模上為業界最大的一個集群。
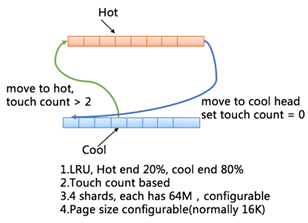
2. 2 Page cache
為了實現 buffer I/O的能力,我們單獨實現了 page cache。Page cahce 採用 touch count based LRU 算法實現。引入 touch count 的意義是為了更好的與數據庫的I/O特性結合。因為數據庫中時常會有大表掃描等行為,我們不希望這種使用頻率低的數據頁沖刷掉 LRU 的效率。我們會基於 touch count 將 page 在 hot 端和 cool 端進行移動。
Page cache 的頁大小可配置,與數據庫的頁大小進行結合時,會發揮更好的 cache 效率。總體上 DBFS 的 page cache 具備以下的能力:
- 基於 touch count 進行 page 的冷熱端遷移
- 冷熱端比例可配置,目前為熱冷比例為2:8
- page size 可配置,結合數據庫頁進行最優化配置
- 多 shard,提高併發;總體容量可配置
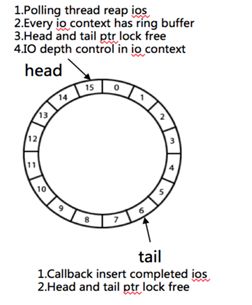
2. 3 異步I/O
為了提高數據庫的I/O吞吐能力,大部分數據庫都使用了異步I/O。我們為了兼容上層數據庫的I/O特性,實現了異步I/O。異步I/O特性:
- 無鎖隊列實現
- 可配置的I/O depth,能夠使得針對數據庫不同的I/O類型進行精確時延控制
- polling adaptive,減少 CPU 消耗
2. 4 原子寫
為了保證數據庫頁寫出的時候不出現 partial write,DBFS 實現了原子寫功能。基於 DBFS 的 Innodb,可以安全的將 double write buffer 關掉,從而使得在存計分離下數據庫帶寬節省 100%。
另外,如 PostgreSQL 使用的是 buffer I/O,也避免了 PG 在 dirty page flush 時偶發性遇到的缺頁問題。
2. 5 Online Resize
為了避免擴容而帶來的數據遷移,DBFS 結合底層盤古實現 volume 的在線 resize。DBFS 有自己的 bitmap allocator,用於實現底層存儲空間的管理。我們對 bitmap allocator 進行了優化,在文件系統層級做到了 lock free 的 resize,使得上層業務可以在任何時候進行對業務無損的高效擴容,完全優於傳統的 ext4 文件系統。
Online Resize 的支持,避免了存儲空間的浪費,因為不用 reserve 如 20% 的存儲空間了,可以做到隨擴隨寫。
以下為擴容時的 bitmap 變化過程:

2. 6 TCP 與 RDMA 互切
RDMA 在集團數據庫大規模的引入使用也是一個非常大的風險點,DBFS 與盤古一起實現了 RDMA 與 TCP 互切的功能,並在全鏈路過程中進行了互換演練,使得 RDMA 的風險在可控的範圍內,穩定性保障更加完善。
另外,DBFS,盤古以及網絡團隊,針對 RDMA 進行了非常多的容量水位壓測,故障演練等工作,為業界最大規模 RDMA 上線做了非常充足的準備。
2. 7 2018 年大促部署
在做到了技術上的突破和攻關后,DBFS 最終完成艱巨的任務通過大促全鏈路的考驗以及雙“十一”大考,再次驗證了存儲計算分離的可行性和整體技術趨勢。
三、存儲中台利器 DBFS
除了以上做為文件系統必須實現的功能以外,DBFS 還實現了諸多的特性,使得業務使用 DBFS 更加的通用化,更加易用性,更加穩定以及安全。
3. 1 技術沉澱與賦能
我們將所有的技術創新和功能以產品的形式沉澱在 DBFS 中,使得 DBFS 能夠賦能更多的業務實現以用戶態的形式訪問不同的底層存儲介質,賦能更多數據庫實現存儲計算分離。
3. 1.1 POSIX 兼容
目前為了支撐數據庫業務,我們兼容了大多數常用的 POSIX 文件接口,以方便上層數據庫業務的對接。另外也實現了 page cache,異步I/O以及原子寫等,為數據庫業務提供豐富的I/O能力。另外,我們也實現了 glibc 的接口,用於支持文件流的操作和處理。這兩種接口的支持,大大簡化了數據庫接入的複雜度,增加了 DBFS 易用性,使得 DBFS 可以支撐更多的數據庫業務。
posix 部分大家比較熟悉就不再列出,以下僅為部分 glibc 接口供參考:
// glibc interface FILE *fopen (constchar*path,constchar*mode); FILE *fdopen (int fildes,constchar*mode); size_t fread (void*ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite (constvoid*ptr, size_t size, size_t nmemb, FILE *stream); intfflush (FILE *stream); intfclose (FILE *stream); intfileno (FILE *stream); intfeof (FILE *stream); intferror (FILE *stream); voidclearerr (FILE *stream); intfseeko (FILE *stream, off_t offset,int whence); intfseek (FILE *stream,long offset,int whence); off_t ftello (FILE *stream); longftell (FILE *stream); voidrewind (FILE *stream);
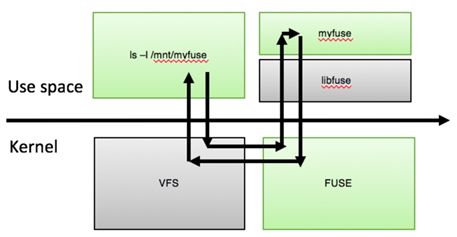
3. 1.2 Fuse 實現
另外,為了兼容 Linux 生態我們實現了 fuse,打通 VFS 的交互。Fuse 的引入使得用戶在不考慮極致性能的情況下,可以不需要任何代碼改動而接入 DBFS,大大提高產品的易用性。另外,也大大方便了傳統的運維操作。

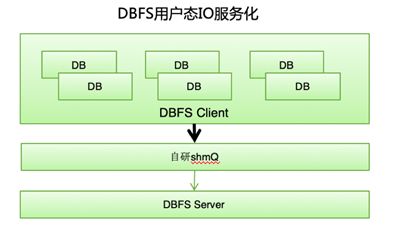
3. 1.3 服務化能力
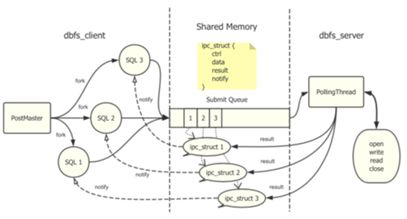
DBFS 自研了 shmQ 組件,基於內享內存的 IPC 通信,從而拉通了對於 PostgreSQL 基於進程架構和 MySQL 基於線程架構的支持,使得 DBFS 更加的通用化和安全,為以後在線升級提供堅實的基礎。
shmQ 基於無鎖實現,性能和吞吐表現優異,從目前測試來看,在 16K 等數據庫大頁下能控制在幾個 us 以內的訪問時延。服務化以及多進程架構的支持,目前性能與穩定性符合預期。
3. 1.4 集群文件系統
集群功能是 DBFS 的又一大明顯特性,賦能數據庫基於 shared-disk 模式,實現計算資源的線性擴展,為業務節省存儲成本。另外,shared-disk 的模式也為數據庫提供了快速的彈性能力,也大大提高了主備快速切換的 SLA。集群文件系統提供一寫多讀以及多點寫入的能力,為數據庫 shared-disk 和 shared nothing 架構打下堅實的基礎。與傳統的 OCFS 相比,我們在用戶態實現,性能更好,更加自主可控。OCFS 嚴重依賴於 Linux 的 VFS,如沒有獨立的 page cache 等。
DBFS 支持一寫多讀模式時,提供多種角色可選(M/S),可以存在一個M節點多個S節點使用共享數據,M 節點和S節點共同訪問盤古數據。上層數據庫對M/S節點進行了限制,M節點的數據訪問是可讀可寫的,S節點的數據訪問是只讀的。如果主庫發生故障,就會進行切換。主從切換步驟:
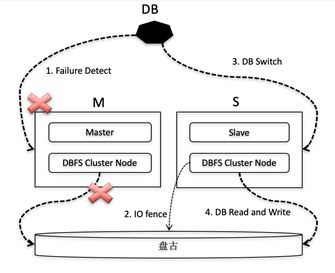
- 業務監控指標探測發現 M 節點出現無法訪問或者異常的時候,進行決策,是否要進行切換。
- 如果發生切換,由管控平台發起切換命令,切換命令完成,代表 DBFS 和上層數據庫都已經完成角色切換。
- 在 DBFS 切換的過程中,最主要的動作就是 IO fence,禁止掉原本的M節點 IO 能力,防止雙寫情況。
DBFS 在多點寫入時,對所有節點進行全局的 metalock 控制,blockgroup allocation 優化等。另外也會涉及到基於 disk 的 quorum 算法等,內容比較複雜,暫不做詳細陳述。
3. 2 軟硬件結合
隨着新存儲介質的出現,數據庫勢必需要借其發揮更好的性能或者更低成本優化,並且做到對底層存儲介質的自主可控。
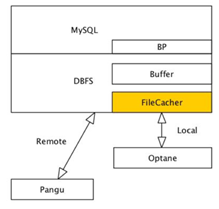
從 Intel 對存儲介質的規劃來看,從性能到容量,會形成 AEP,Optane 和 SSD 這三種產品,而在向大容量方向上,又會有 QLC 的出現。所以綜合性能和成本來看,我們覺得 Optane 是一個比較不錯的 cache 產品。我們選擇它作為 DBFS 機頭持久化 filecache 的實現。

3. 2.1 持久化 file cache
DBFS 實現了基於 Optane 的 local 持久化 cache 功能,使得在存計分離下更近一步提升數據庫的讀寫性能。File cache 為了達到生產可用性,做了非常多的工作,如:
- 穩定可靠的故障處理
- 支持動態 enable 和 disable
- 支持負載均衡
- 支持性能指標採集和展示
- 支持數據正確性 scrub
這些功能的支撐,為線上穩定性打下堅實的基礎。其中,針對 Optane 的I/O為 SPDK 的純用戶態技術,DBFS 結合 Fusion Engine 的 vhost 實現。File Cache 的頁大小可以根據上層數據庫的 block 大小進行最佳配置,以達到最好的效果。
以下為 file cache 的架構圖:

以下是測試所得讀寫性能收益數據:
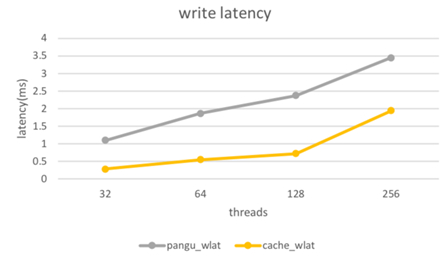
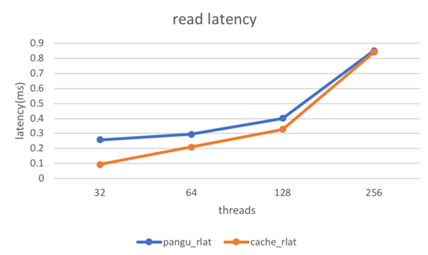
其中帶有“cache”的為基於 filecache 所得。整體表現隨着命中率提高,讀時延開始下降。另外,我們針對 file cache,進行了諸多性能指標的監控。
3. 2.2 Open Channel SSD
X-Engine 和 DBFS 以及 Fusion Engine 團隊展開合作,基於 object SSD 進一步打造存儲自主可控的系統。在降低 SSD 磨損,提高 SSD 吞吐,降低讀寫相互干擾等領域,進行了深度探索與實踐,都取得了非常不錯的效果。目前已經結合X-Engine 的分層存儲策略,打通了讀寫路徑,我們期待下一步更加深入的智能化存儲研發。
四、總結與展望
2018 年 DBFS 已經大規模支持了X-DB 以存儲計算分離形態支持“11.11”大促;與此同時也賦能 ADS 實現一寫多讀能力以及 Tair 等。
在支持業務的同時,DBFS 本身已經拉通了 PG 進程與 MySQL 線程架構的支持,打通了 VFS 接口,做到了與 Linux 生態的兼容,成為真正意義上的存儲中台級產品——集群用戶態文件系統。未來結合更多的軟硬件結合、分層存儲、NVMeoF 等技術賦能更多的數據庫,實現其更大的價值。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【精選推薦文章】
帶您來了解什麼是 USB CONNECTOR ?
為什麼 USB CONNECTOR 是電子產業重要的元件?
又掌控什麼技術要點? 帶您認識其相關發展及效能