使用Amazon EMR和Apache Hudi在S3上插入,更新,刪除數據
將數據存儲在Amazon S3中可帶來很多好處,包括規模、可靠性、成本效率等方面。最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之類的開源工具來處理和分析數據。 儘管這些工具功能強大,但是在處理需要進行增量數據處理以及記錄級別插入,更新和刪除場景時,仍然非常具有挑戰。
與客戶交談時,我們發現有些場景需要處理對單條記錄的增量更新,例如:
- 遵守數據隱私法規,在該法規中,用戶選擇忘記或更改應用程序對數據使用方式的協議。
- 使用流數據,當你必須要處理特定的數據插入和更新事件時。
- 實現變更數據捕獲(CDC)架構來跟蹤和提取企業數據倉庫或運營數據存儲中的數據庫變更日誌。
- 恢復遲到的數據,或分析特定時間點的數據。
從今天開始,EMR 5.28.0版包含Apache Hudi(孵化中),因此你不再需要構建自定義解決方案來執行記錄級別的插入,更新和刪除操作。Hudi是Uber於2016年開始開發,以解決攝取和ETL管道效率低下的問題。最近幾個月,EMR團隊與Apache Hudi社區緊密合作,提供了一些補丁,包括將Hudi更新為Spark 2.4.4,支持Spark Avro,增加了對AWS Glue Data Catalog的支持,以及多個缺陷修復。
使用Hudi,即可以在S3上執行記錄級別的插入,更新和刪除,從而使你能夠遵守數據隱私法律、消費實時流、捕獲更新的數據、恢復遲到的數據和以開放的、供應商無關的格式跟蹤歷史記錄和回滾。 創建數據集和表,然後Hudi管理底層數據格式。Hudi使用Apache Parquet和Apache Avro進行數據存儲,並內置集成Spark,Hive和Presto,使你能夠使用與現在所使用的相同工具來查詢Hudi數據集,並且幾乎實時地訪問新數據。
啟動EMR群集時,只要選擇以下組件之一(Hive,Spark,Presto),就可以自動安裝和配置Hudi的庫和工具。你可以使用Spark創建新的Hudi數據集,以及插入,更新和刪除數據。每個Hudi數據集都會在集群的已配置元存儲庫(包括AWS Glue Data Catalog)中進行註冊,並显示為可以通過Spark,Hive和Presto查詢的表。
Hudi支持兩種存儲類型,這些存儲類型定義了如何寫入,索引和從S3讀取數據:
-
寫時複製(Copy On Write)– 數據以列格式(Parquet)存儲,並且在寫入時更新數據數據會創建新版本文件。此存儲類型最適合用於讀取繁重的工作負載,因為數據集的最新版本在高效的列式文件中始終可用。
-
讀時合併(Merge On Read)– 將組合列(Parquet)格式和基於行(Avro)格式來存儲數據; 更新記錄至基於行的
增量文件中,並在以後進行壓縮,以創建列式文件的新版本。 此存儲類型最適合於繁重的寫工作負載,因為新提交(commit)會以增量文件格式快速寫入,但是要讀取數據集,則需要將壓縮的列文件與增量文件合併。
下面讓我們快速預覽下如何在EMR集群中設置和使用Hudi數據集。
結合Apache Hudi與Amazon EMR
從EMR控制台開始創建集群。在高級選項中,選擇EMR版本5.28.0(第一個包括Hudi的版本)和以下應用程序:Spark,Hive和Tez。在硬件選項中,添加了3個任務節點,以確保有足夠的能力運行Spark和Hive。
群集就緒后,使用在安全性選項中選擇的密鑰對,通過SSH進入主節點並訪問Spark Shell。 使用以下命令來啟動Spark Shell以將其與Hudi一起使用:
$ spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
--conf "spark.sql.hive.convertMetastoreParquet=false"
--jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar使用以下Scala代碼將一些示例ELB日誌導入寫時複製存儲類型的Hudi數據集中:
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions._
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
//Set up various input values as variables
val inputDataPath = "s3://athena-examples-us-west-2/elb/parquet/year=2015/month=1/day=1/"
val hudiTableName = "elb_logs_hudi_cow"
val hudiTablePath = "s3://MY-BUCKET/PATH/" + hudiTableName
// Set up our Hudi Data Source Options
val hudiOptions = Map[String,String](
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> "request_ip",
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> "request_verb",
HoodieWriteConfig.TABLE_NAME -> hudiTableName,
DataSourceWriteOptions.OPERATION_OPT_KEY ->
DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "request_timestamp",
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> hudiTableName,
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> "request_verb",
DataSourceWriteOptions.HIVE_ASSUME_DATE_PARTITION_OPT_KEY -> "false",
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY ->
classOf[MultiPartKeysValueExtractor].getName)
// Read data from S3 and create a DataFrame with Partition and Record Key
val inputDF = spark.read.format("parquet").load(inputDataPath)
// Write data into the Hudi dataset
inputDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.mode(SaveMode.Overwrite)
.save(hudiTablePath)在Spark Shell中,現在就可以計算Hudi數據集中的記錄:
scala> inputDF2.count()
res1: Long = 10491958在選項(options)中,使用了與為集群中的Hive Metastore集成,以便在默認數據庫(default)中創建表。 通過這種方式,我可以使用Hive查詢Hudi數據集中的數據:
hive> use default;
hive> select count(*) from elb_logs_hudi_cow;
...
OK
10491958現在可以更新或刪除數據集中的單條記錄。 在Spark Shell中,設置了一些用來查詢更新記錄的變量,並準備用來選擇要更改的列的值的SQL語句:
val requestIpToUpdate = "243.80.62.181"
val sqlStatement = s"SELECT elb_name FROM elb_logs_hudi_cow WHERE request_ip = '$requestIpToUpdate'"執行SQL語句以查看列的當前值:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_003|
+------------+然後,選擇並更新記錄:
// Create a DataFrame with a single record and update column value
val updateDF = inputDF.filter(col("request_ip") === requestIpToUpdate)
.withColumn("elb_name", lit("elb_demo_001"))現在用一種類似於創建Hudi數據集的語法來更新它。 但是這次寫入的DataFrame僅包含一條記錄:
// Write the DataFrame as an update to existing Hudi dataset
updateDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,
DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
.mode(SaveMode.Append)
.save(hudiTablePath)在Spark Shell中,檢查更新的結果:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_001|
+------------+現在想刪除相同的記錄。要刪除它,可在寫選項中傳入了EmptyHoodieRecordPayload有效負載:
// Write the DataFrame with an EmptyHoodieRecordPayload for deleting a record
updateDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,
DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY,
"org.apache.hudi.EmptyHoodieRecordPayload")
.mode(SaveMode.Append)
.save(hudiTablePath)在Spark Shell中,可以看到該記錄不再可用:
scala> spark.sql(sqlStatement).show()
+--------+
|elb_name|
+--------+
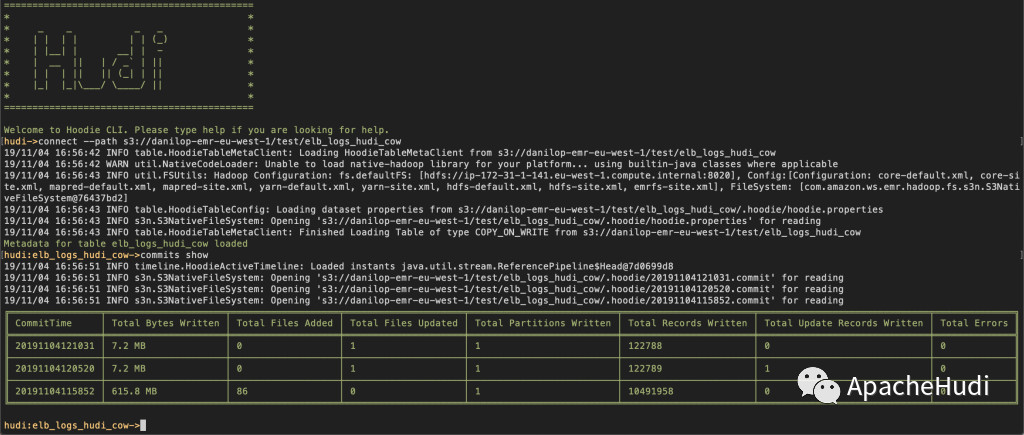
+--------+Hudi是如何管理所有的更新和刪除? 我們可以通過Hudi命令行界面(CLI)連接到數據集,便可以看到這些更改被解釋為提交(commits):
可以看到,此數據集是寫時複製數據集,這意味着每次對記錄進行更新時,包含該記錄的文件將被重寫以包含更新后的值。 你可以查看每次提交(commit)寫入了多少記錄。表格的底行描述了數據集的初始創建,上方是單條記錄更新,頂部是單條記錄刪除。
使用Hudi,你可以回滾到每個提交。 例如,可以使用以下方法回滾刪除操作:
hudi:elb_logs_hudi_cow->commit rollback --commit 20191104121031在Spark Shell中,記錄現在回退到更新之後的位置:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_001|
+------------+寫入時複製是默認存儲類型。 通過將其添加到我們的hudiOptions中,我們可以重複上述步驟來創建和更新讀時合併數據集類型:
DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY -> "MERGE_ON_READ"如果更新讀時合併數據集並使用Hudi CLI查看提交(commit)時,則可以看到讀時合併與寫時複製相比有何不同。使用讀時合併,你僅寫入更新的行,而不像寫時複製一樣寫入整個文件。這就是為什麼讀時合併對於需要更多寫入或使用較少讀取次數更新或刪除繁重工作負載的用例很有幫助的原因。增量提交作為Avro記錄(基於行的存儲)寫入磁盤,而壓縮數據作為Parquet文件(列存儲)寫入。為避免創建過多的增量文件,Hudi會自動壓縮數據集,以便使得讀取盡可能地高效。
創建讀時合併數據集時,將創建兩個Hive表:
- 第一個表的名稱與數據集的名稱相同。
- 第二個表的名稱後面附加了字符_rt; _rt後綴表示實時。
查詢時,第一個表返回已壓縮的數據,並不會显示最新的增量提交。使用此表可提供最佳性能,但會忽略最新數據。查詢實時表會將壓縮的數據與讀取時的增量提交合併,因此該數據集稱為讀時合併。這將導致可以使用最新數據,但會導致性能開銷,並且性能不如查詢壓縮數據。這樣,數據工程師和分析人員可以靈活地在性能和數據新鮮度之間進行選擇。
已可用
EMR 5.28.0的所有地區現在都可以使用此新功能。將Hudi與EMR結合使用無需額外費用。你可以在EMR文檔中了解更多有關Hudi的信息。 這個新工具可以簡化你在S3中處理,更新和刪除數據的方式。也讓我們知道你打算將其用於哪些場景!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益