QTI EAS學習之find_energy_efficient_cpu_如何寫文案
※教你寫出一流的銷售文案?
銷售文案是什麼?A文案是廣告用的文字。舉凡任何宣傳、行銷、販賣商品時所用到的文字都是文案。在網路時代,文案成為行銷中最重要的宣傳方式,好的文案可節省大量宣傳資源,達成行銷目的。
Energy Awareness Scheduler是由ARM和Linaro開發的新的linux kernel調度器。
原先CFS調度器是基於policy進行調度,並有不同的吞吐量。例如,有一個新的task創建,同時也有一個idle cpu時,CFS始終會把新的task放到這個idle cpu上運行。但是,這樣對節省功耗來說,並不是一個最好的決定。而EAS就是為了解決這樣的問題。在不影響性能的前提下,EAS會在調度時實現節省功耗。
從SDM845開始,QTI在EAS基礎上進行了一些修改,以滿足移動市場的需要。所以QTI在EAS基礎上添加了一些feature,來獲得更好的性能和功耗。
Energy model
在dts中,針對不同的cpu平台,已定義好不同的energy model。模型主要是由【頻率,能量】的數組構成,對應了CPU和cluster不同的OOP(Operating Performance Point);同時也提供了不同idle state的能量消耗:idle cost。
CPU0: cpu@0 { device_type = "cpu"; compatible = "arm,armv8"; reg = <0x0 0x0>; enable-method = "psci"; efficiency = <1024>; cache-size = <0x8000>; cpu-release-addr = <0x0 0x90000000>; qcom,lmh-dcvs = <&lmh_dcvs0>; #cooling-cells = <2>; next-level-cache = <&L2_0>; sched-energy-costs = <&CPU_COST_0 &CLUSTER_COST_0>; //小核都用CPU_COST_0 CLUSTER_COST_0 。。。。。。 CPU4: cpu@400 { device_type = "cpu"; compatible = "arm,armv8"; reg = <0x0 0x400>; enable-method = "psci"; efficiency = <1740>; cache-size = <0x20000>; cpu-release-addr = <0x0 0x90000000>; qcom,lmh-dcvs = <&lmh_dcvs1>; #cooling-cells = <2>; next-level-cache = <&L2_400>; sched-energy-costs = <&CPU_COST_1 &CLUSTER_COST_1>; //大核都用CPU_COST_1 CLUSTER_COST_1
。。。。。。。
對應的數組如下,
energy_costs: energy-costs { compatible = "sched-energy"; CPU_COST_0: core-cost0 { busy-cost-data = < 300000 31 422400 38 499200 42 576000 46 652800 51 748800 58 825600 64 902400 70 979200 76 1056000 83 1132800 90 1209600 97 1286400 105 1363200 114 1440000 124 1516800 136 1593600 152 1651200 167 /* speedbin 0,1 */ 1670400 173 /* speedbin 2 */ 1708800 186 /* speedbin 0,1 */ 1747200 201 /* speedbin 2 */ >; idle-cost-data = < 22 18 14 12 >; }; CPU_COST_1: core-cost1 { busy-cost-data = < 300000 258 422400 260 499200 261 576000 263 652800 267 729600 272 806400 280 883200 291 960000 305 1036800 324 1113600 348 1190400 378 1267200 415 1344000 460 1420800 513 1497600 576 1574400 649 1651200 732 1728000 824 1804800 923 1881600 1027 1958400 1131 2035000 1228 /* speedbin 1,2 */ 2092000 1290 /* speedbin 1 */ 2112000 1308 /* speedbin 2 */ 2208000 1363 /* speedbin 2 */ >; idle-cost-data = < 100 80 60 40 >; }; CLUSTER_COST_0: cluster-cost0 { busy-cost-data = < 300000 3 422400 4 499200 4 576000 4 652800 5 748800 5 825600 6 902400 7 979200 7 1056000 8 1132800 9 1209600 9 1286400 10 1363200 11 1440000 12 1516800 13 1593600 15 1651200 17 /* speedbin 0,1 */ 1670400 19 /* speedbin 2 */ 1708800 21 /* speedbin 0,1 */ 1747200 23 /* speedbin 2 */ >; idle-cost-data = < 4 3 2 1 >; }; CLUSTER_COST_1: cluster-cost1 { busy-cost-data = < 300000 24 422400 24 499200 25 576000 25 652800 26 729600 27 806400 28 883200 29 960000 30 1036800 32 1113600 34 1190400 37 1267200 40 1344000 45 1420800 50 1497600 57 1574400 64 1651200 74 1728000 84 1804800 96 1881600 106 1958400 113 2035000 120 /* speedbin 1,2 */ 2092000 125 /* speedbin 1 */ 2112000 127 /* speedbin 2 */ 2208000 130 /* speedbin 2 */ >; idle-cost-data = < 4 3 2 1 >; }; }; /* energy-costs */
在代碼kernel/sched/energy.c中遍歷所有cpu,並讀取dts中的數據
for_each_possible_cpu(cpu) { cn = of_get_cpu_node(cpu, NULL); if (!cn) { pr_warn("CPU device node missing for CPU %d\n", cpu); return; } if (!of_find_property(cn, "sched-energy-costs", NULL)) { pr_warn("CPU device node has no sched-energy-costs\n"); return; } for_each_possible_sd_level(sd_level) { cp = of_parse_phandle(cn, "sched-energy-costs", sd_level); if (!cp) break; prop = of_find_property(cp, "busy-cost-data", NULL); if (!prop || !prop->value) { pr_warn("No busy-cost data, skipping sched_energy init\n"); goto out; } sge = kcalloc(1, sizeof(struct sched_group_energy), GFP_NOWAIT); if (!sge) goto out; nstates = (prop->length / sizeof(u32)) / 2; cap_states = kcalloc(nstates, sizeof(struct capacity_state), GFP_NOWAIT); if (!cap_states) { kfree(sge); goto out; } for (i = 0, val = prop->value; i < nstates; i++) { //將讀取的[freq,energy]數組存放起來 cap_states[i].cap = SCHED_CAPACITY_SCALE; cap_states[i].frequency = be32_to_cpup(val++); cap_states[i].power = be32_to_cpup(val++); } sge->nr_cap_states = nstates; //state為[freq,energy]組合個數,就是支持多少個狀態:將所有數據flatten之後,再處以2 sge->cap_states = cap_states; prop = of_find_property(cp, "idle-cost-data", NULL); if (!prop || !prop->value) { pr_warn("No idle-cost data, skipping sched_energy init\n"); kfree(sge); kfree(cap_states); goto out; } nstates = (prop->length / sizeof(u32)); idle_states = kcalloc(nstates, sizeof(struct idle_state), GFP_NOWAIT); if (!idle_states) { kfree(sge); kfree(cap_states); goto out; } for (i = 0, val = prop->value; i < nstates; i++) idle_states[i].power = be32_to_cpup(val++); //將讀取的idle cost data存放起來 sge->nr_idle_states = nstates; //idle state的個數,就是idle cost data的長度 sge->idle_states = idle_states; sge_array[cpu][sd_level] = sge; //將當前cpu獲取的energy模型存放再sge_array[cpu][sd_level]中。其中cpu就是對應哪個cpu,sd_level則對應是哪個sched_domain,也就是是cpu level還是cluster level } }
Load Tracking
QTI EAS使用的負載計算是WALT,是基於時間窗口的load統計方法,具體參考之前文章:https://www.cnblogs.com/lingjiajun/p/12317090.html
其中會跟蹤計算出2個比較關鍵的數據,就是task_util和cpu_util
當執行wakeup task placement,scheduler就會使用task utilization和CPU utilization
可以理解為將load的情況轉化為Utilization,並且將其標準化為1024的值。
task_util = demand *1024 / window_size
= (delta / window_size) * (cur_freq / max_freq) * cpu_max_capacity
—–delta是task在一個window中運行的真實時間;window_size默認是20ms;
cur_freq為cpu當前頻率;max_freq為cpu最大頻率;
Task utilization boosted = Task utilization + (1024-task_util) x boost_percent —–boost percent是使用schedtune boost時,所需要乘上的百分比
CPU utilization = 1024 x (累計的runnable均值 / window size)——–累計的runnable均值,個人理解就是rq上所有task util的總和
Task placement的主要概念:
EAS是Task placement 是EAS影響調度的主要模塊。 其主要keypoint如下:
1、EAS依靠energy model來進行精確地進行選擇CPU運行
2、使用energy model估算:把一個任務安排在一個CPU上,或者將任務從一個CPU遷移到另一個CPU上,所發生的能量變化
3、EAS會在不影響performance情況下(比如滿足滿足最低的latency),趨向於選擇消耗能量最小的CPU,去運行當前的task
4、EAS僅發生在system沒有overutilized的情況下
5、EAS的概念與QTI EAS的一樣
6、一旦系統處於overutilized,QTI EAS仍然在wake up的path下進行energy aware。不會考慮系統overutilized的情形。
補充:
※別再煩惱如何寫文案,掌握八大原則!
什麼是銷售文案服務?A就是幫你撰寫適合的廣告文案。當您需要販售商品、宣傳活動、建立個人品牌,撰寫廣告文案都是必須的工作。
overutilization,一個cpu_util大於cpu capacity的95%(sched_capacity_margin_up[cpu]),那麼就認為這個cpu處於overutilization。並且整個系統也被認為overutilizaion。
EAS核心調度算法
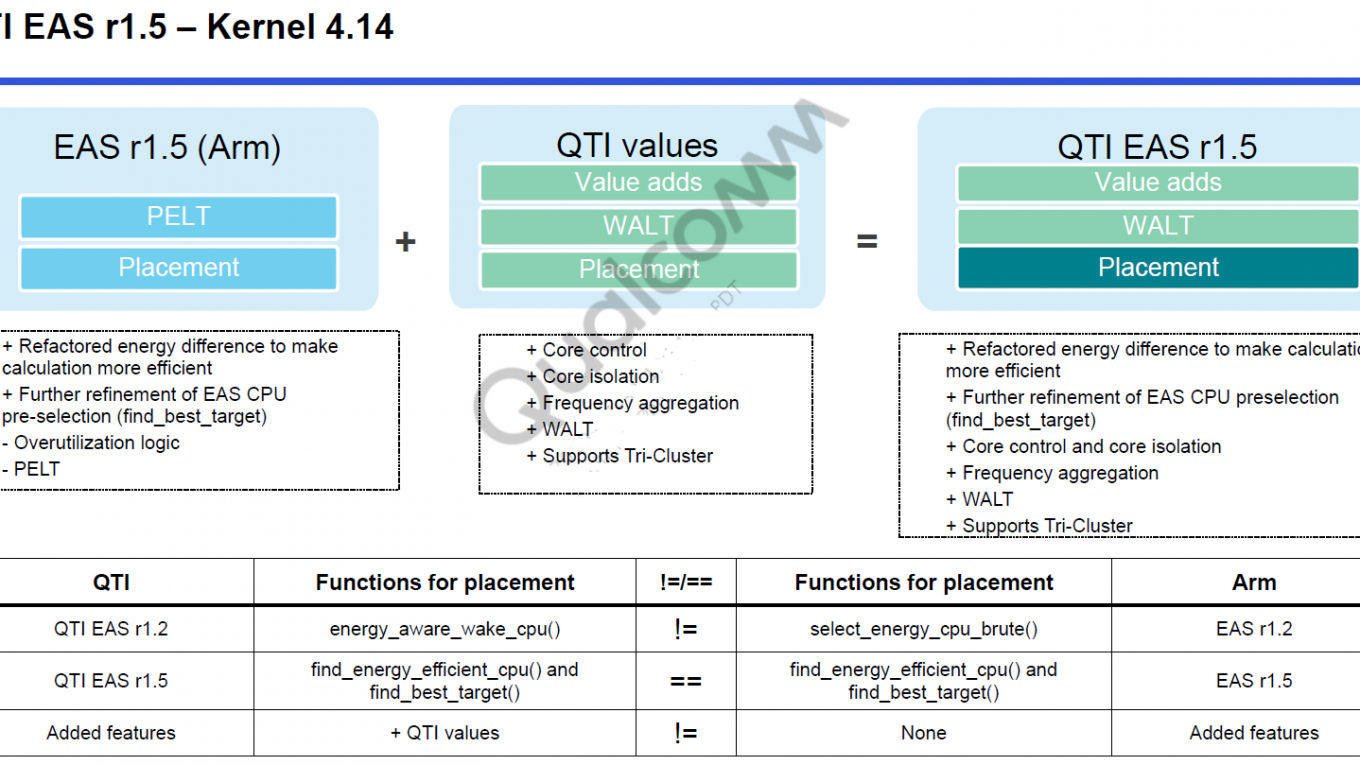
不同版本的EAS在不同版本下的主要task placement實現函數(針對CFS task):
Zone scheduler: select_best_cpu() QTI EAS r1.2: energy_aware_wake_cpu() QTI EAS r1.5: find_energy_efficienct_cpu()
task placement調用路徑:
QTI EAS r1.5 (Kernel 4.14) Task wake-up: try_to_wake_up() →select_task_rq_fair() →invokes find_energy_efficient_cpu() Scheduler tick occurs: scheduler_tick() →check_for_migration() →invokes find_energy_efficient_cpu() New task arrives: do_fork() →wake_up_new_task() →select_task_rq_fair() →invokes find_energy_efficient_cpu()
EAS的task placement代碼流程,主要目標是找到一個合適的cpu來運行當前這個task p。
主要代碼就是find_energy_efficient_cpu()這個函數裏面,如下:
1 /* 2 * find_energy_efficient_cpu(): Find most energy-efficient target CPU for the 3 * waking task. find_energy_efficient_cpu() looks for the CPU with maximum 4 * spare capacity in each performance domain and uses it as a potential 5 * candidate to execute the task. Then, it uses the Energy Model to figure 6 * out which of the CPU candidates is the most energy-efficient. 7 * 8 * The rationale for this heuristic is as follows. In a performance domain, 9 * all the most energy efficient CPU candidates (according to the Energy 10 * Model) are those for which we'll request a low frequency. When there are 11 * several CPUs for which the frequency request will be the same, we don't 12 * have enough data to break the tie between them, because the Energy Model 13 * only includes active power costs. With this model, if we assume that 14 * frequency requests follow utilization (e.g. using schedutil), the CPU with 15 * the maximum spare capacity in a performance domain is guaranteed to be among 16 * the best candidates of the performance domain. 17 * 18 * In practice, it could be preferable from an energy standpoint to pack 19 * small tasks on a CPU in order to let other CPUs go in deeper idle states, 20 * but that could also hurt our chances to go cluster idle, and we have no 21 * ways to tell with the current Energy Model if this is actually a good 22 * idea or not. So, find_energy_efficient_cpu() basically favors 23 * cluster-packing, and spreading inside a cluster. That should at least be 24 * a good thing for latency, and this is consistent with the idea that most 25 * of the energy savings of EAS come from the asymmetry of the system, and 26 * not so much from breaking the tie between identical CPUs. That's also the 27 * reason why EAS is enabled in the topology code only for systems where 28 * SD_ASYM_CPUCAPACITY is set. 29 * 30 * NOTE: Forkees are not accepted in the energy-aware wake-up path because 31 * they don't have any useful utilization data yet and it's not possible to 32 * forecast their impact on energy consumption. Consequently, they will be 33 * placed by find_idlest_cpu() on the least loaded CPU, which might turn out 34 * to be energy-inefficient in some use-cases. The alternative would be to 35 * bias new tasks towards specific types of CPUs first, or to try to infer 36 * their util_avg from the parent task, but those heuristics could hurt 37 * other use-cases too. So, until someone finds a better way to solve this, 38 * let's keep things simple by re-using the existing slow path. 39 */ 40 41 static int find_energy_efficient_cpu(struct task_struct *p, int prev_cpu, 42 int sync, int sibling_count_hint) 43 { 44 unsigned long prev_energy = ULONG_MAX, best_energy = ULONG_MAX; 45 struct root_domain *rd = cpu_rq(smp_processor_id())->rd; 46 int weight, cpu = smp_processor_id(), best_energy_cpu = prev_cpu; //cpu:當前執行的cpu 47 unsigned long cur_energy; 48 struct perf_domain *pd; 49 struct sched_domain *sd; 50 cpumask_t *candidates; 51 bool is_rtg; 52 struct find_best_target_env fbt_env; 53 bool need_idle = wake_to_idle(p); //是否set flag PF_WAKE_UP_IDLE 54 int placement_boost = task_boost_policy(p); //獲取task sched boost policy:none/on_big/on_all 與sched_boost、schedtune設置也有關 55 u64 start_t = 0; 56 int delta = 0; 57 int task_boost = per_task_boost(p); //僅網絡有打開該boost,這裏可以認為沒有boost 58 int boosted = (schedtune_task_boost(p) > 0) || (task_boost > 0); //查看task的schedtune有沒有打開boost 59 int start_cpu = get_start_cpu(p); //獲取從哪個cpu core開始,嘗試作為target cpu 60 61 if (start_cpu < 0) 62 goto eas_not_ready; 63 64 is_rtg = task_in_related_thread_group(p); //判斷task是否在一個group內 65 66 fbt_env.fastpath = 0; 67 68 if (trace_sched_task_util_enabled()) 69 start_t = sched_clock(); //trace log 70 71 /* Pre-select a set of candidate CPUs. */ 72 candidates = this_cpu_ptr(&energy_cpus); 73 cpumask_clear(candidates); 74 75 if (need_idle) 76 sync = 0; 77 78 if (sysctl_sched_sync_hint_enable && sync && 79 bias_to_this_cpu(p, cpu, start_cpu)) { //滿足3個調節:sync hint enable/flag:sync=1/bias to當前cpu 80 best_energy_cpu = cpu; //當前執行的cpu 81 fbt_env.fastpath = SYNC_WAKEUP; 82 goto done; 83 } 84 85 if (is_many_wakeup(sibling_count_hint) && prev_cpu != cpu && //sibling_count_hint代表有多少個thread在當前event中喚醒 86 bias_to_this_cpu(p, prev_cpu, start_cpu)) { 87 best_energy_cpu = prev_cpu; //選擇prev cpu 88 fbt_env.fastpath = MANY_WAKEUP; 89 goto done; 90 } 91 92 rcu_read_lock(); 93 pd = rcu_dereference(rd->pd); 94 if (!pd) 95 goto fail; 96 97 /* 98 * Energy-aware wake-up happens on the lowest sched_domain starting 99 * from sd_asym_cpucapacity spanning over this_cpu and prev_cpu. 100 */ 101 sd = rcu_dereference(*this_cpu_ptr(&sd_asym_cpucapacity)); 102 while (sd && !cpumask_test_cpu(prev_cpu, sched_domain_span(sd))) 103 sd = sd->parent; 104 if (!sd) 105 goto fail; 106 107 sync_entity_load_avg(&p->se); //更新task所在sched_entity的PELT load 108 if (!task_util_est(p)) 109 goto unlock; 110 111 if (sched_feat(FIND_BEST_TARGET)) { //檢查FIND_BEST_TARGET這個調度特性是否打開:目前是打開的 112 fbt_env.is_rtg = is_rtg; 113 fbt_env.placement_boost = placement_boost; 114 fbt_env.need_idle = need_idle; 115 fbt_env.start_cpu = start_cpu; 116 fbt_env.boosted = boosted; 117 fbt_env.strict_max = is_rtg && 118 (task_boost == TASK_BOOST_STRICT_MAX); 119 fbt_env.skip_cpu = is_many_wakeup(sibling_count_hint) ? 120 cpu : -1; 121 122 find_best_target(NULL, candidates, p, &fbt_env); //(1)核心函數,最終是將找到的target_cpu和backup_cpu都存放進了candidates中 123 } else { 124 select_cpu_candidates(sd, candidates, pd, p, prev_cpu); 125 } 126 127 /* Bail out if no candidate was found. */ 128 weight = cpumask_weight(candidates); //判斷如果沒有找到target cpu和backup cpu時,直接goto unlock 129 if (!weight) 130 goto unlock; 131 132 /* If there is only one sensible candidate, select it now. */ 133 cpu = cpumask_first(candidates); 134 if (weight == 1 && ((schedtune_prefer_idle(p) && idle_cpu(cpu)) || //如果只找到了1個cpu,task是prefer_idle並且這個cpu也是idle的;或者cpu就是prev_cpu 135 (cpu == prev_cpu))) { 136 best_energy_cpu = cpu; //那麼就選這個cpu為【best_energy_cpu】 137 goto unlock; 138 } 139 140 #ifdef CONFIG_SCHED_WALT 141 if (p->state == TASK_WAKING) //如果是新喚醒的task,獲取task_util 142 delta = task_util(p); 143 #endif 144 if (task_placement_boost_enabled(p) || need_idle || boosted || //滿足一下條件之一,那麼第一個candidate cpu就作為【best_energy_cpu】不再考慮計算energy 145 is_rtg || __cpu_overutilized(prev_cpu, delta) || //打開了sched_boost、need_idle(PF_WAKE_UP_IDLE)、開了schedtune boost、related_thread_group限制使用小核、prev_cpu+delta沒有overutil、 146 !task_fits_max(p, prev_cpu) || cpu_isolated(prev_cpu)) { //p放在prev_cpu上會misfit、prev_cpu處於isolated 147 best_energy_cpu = cpu; 148 goto unlock; 149 } 150 151 if (cpumask_test_cpu(prev_cpu, &p->cpus_allowed)) //根據prev_cpu是否在task p的cpuset範圍內 152 prev_energy = best_energy = compute_energy(p, prev_cpu, pd); //(2)在範圍內,則計算p在prev_cpu上的energy 153 else 154 prev_energy = best_energy = ULONG_MAX; //不在範圍內,energy就設為最大,說明prev_cpu不考慮作為best_energy_cpu了 155 156 /* Select the best candidate energy-wise. */ //通過比較energy,挑選出best_energy_cpu、best_energy 157 for_each_cpu(cpu, candidates) { 158 if (cpu == prev_cpu) //過濾prev_cpu 159 continue; 160 cur_energy = compute_energy(p, cpu, pd); //計算p遷移到candidate cpu上的energy 161 trace_sched_compute_energy(p, cpu, cur_energy, prev_energy, 162 best_energy, best_energy_cpu); 163 if (cur_energy < best_energy) { 164 best_energy = cur_energy; 165 best_energy_cpu = cpu; 166 } else if (cur_energy == best_energy) { 167 if (select_cpu_same_energy(cpu, best_energy_cpu, //當candidate cpu的energy與best_cpu一樣的話,怎麼選 168 prev_cpu)) { 169 best_energy = cur_energy; 170 best_energy_cpu = cpu; 171 } 172 } 173 } 174 unlock: 175 rcu_read_unlock(); 176 177 /* 178 * Pick the prev CPU, if best energy CPU can't saves at least 6% of 179 * the energy used by prev_cpu. 180 */ 181 if ((prev_energy != ULONG_MAX) && (best_energy_cpu != prev_cpu) && //找到了非prev_cpu的best_energy_cpu、且省電下來的energy要大於在prev_energy上的6%,那麼best_energy_cpu則滿足條件;否則仍然使用prev_cpu 182 ((prev_energy - best_energy) <= prev_energy >> 4)) //這裏巧妙地使用了位移:右移1位代表÷2,所以prev_energy/2/2/2/2 = prev_energy*6% 183 best_energy_cpu = prev_cpu; 184 185 done: 186 187 trace_sched_task_util(p, cpumask_bits(candidates)[0], best_energy_cpu, 188 sync, need_idle, fbt_env.fastpath, placement_boost, 189 start_t, boosted, is_rtg, get_rtg_status(p), start_cpu); 190 191 return best_energy_cpu; 192 193 fail: 194 rcu_read_unlock(); 195 eas_not_ready: 196 return -1; 197 }
(1)find_best_target()
1 static void find_best_target(struct sched_domain *sd, cpumask_t *cpus, 2 struct task_struct *p, 3 struct find_best_target_env *fbt_env) 4 { 5 unsigned long min_util = boosted_task_util(p); //獲取p的boosted_task_util 6 unsigned long target_capacity = ULONG_MAX; 7 unsigned long min_wake_util = ULONG_MAX; 8 unsigned long target_max_spare_cap = 0; 9 unsigned long best_active_util = ULONG_MAX; 10 unsigned long best_active_cuml_util = ULONG_MAX; 11 unsigned long best_idle_cuml_util = ULONG_MAX; 12 bool prefer_idle = schedtune_prefer_idle(p); //獲取task prefer_idle配置 13 bool boosted = fbt_env->boosted; 14 /* Initialise with deepest possible cstate (INT_MAX) */ 15 int shallowest_idle_cstate = INT_MAX; 16 struct sched_domain *start_sd; 17 struct sched_group *sg; 18 int best_active_cpu = -1; 19 int best_idle_cpu = -1; 20 int target_cpu = -1; 21 int backup_cpu = -1; 22 int i, start_cpu; 23 long spare_wake_cap, most_spare_wake_cap = 0; 24 int most_spare_cap_cpu = -1; 25 int prev_cpu = task_cpu(p); 26 bool next_group_higher_cap = false; 27 int isolated_candidate = -1; 28 29 /* 30 * In most cases, target_capacity tracks capacity_orig of the most 31 * energy efficient CPU candidate, thus requiring to minimise 32 * target_capacity. For these cases target_capacity is already 33 * initialized to ULONG_MAX. 34 * However, for prefer_idle and boosted tasks we look for a high 35 * performance CPU, thus requiring to maximise target_capacity. In this 36 * case we initialise target_capacity to 0. 37 */ 38 if (prefer_idle && boosted) 39 target_capacity = 0; 40 41 if (fbt_env->strict_max) 42 most_spare_wake_cap = LONG_MIN; 43 44 /* Find start CPU based on boost value */ 45 start_cpu = fbt_env->start_cpu; 46 /* Find SD for the start CPU */ 47 start_sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, start_cpu)); //找到start cpu所在的sched domain,sd_asym_cpucapacity表示是非對稱cpu capacity級別,應該就是DIE level,所以domain是cpu0-7 48 if (!start_sd) 49 goto out; 50 51 /* fast path for prev_cpu */ 52 if (((capacity_orig_of(prev_cpu) == capacity_orig_of(start_cpu)) || //prev cpu和start cpu的當前max_policy_freq下的capacity相等 53 asym_cap_siblings(prev_cpu, start_cpu)) && 54 !cpu_isolated(prev_cpu) && cpu_online(prev_cpu) && 55 idle_cpu(prev_cpu)) { 56 57 if (idle_get_state_idx(cpu_rq(prev_cpu)) <= 1) { //prev cpu idle state的index <1,說明休眠不深 58 target_cpu = prev_cpu; 59 60 fbt_env->fastpath = PREV_CPU_FASTPATH; 61 goto target; 62 } 63 } 64 65 /* Scan CPUs in all SDs */ 66 sg = start_sd->groups; 67 do { //do-while循環,針對start cpu的調度域中的所有調度組進行遍歷,由於domain是cpu0-7,那麼調度組就是2個大小cluster:cpu0-3,cpu4-7 68 for_each_cpu_and(i, &p->cpus_allowed, sched_group_span(sg)) { //尋找task允許的cpuset和調度組可用cpu範圍內 69 unsigned long capacity_curr = capacity_curr_of(i); //當前freq的cpu_capacity 70 unsigned long capacity_orig = capacity_orig_of(i); //當前max_policy_freq的cpu_capacity, >=capacity_curr 71 unsigned long wake_util, new_util, new_util_cuml; 72 long spare_cap; 73 int idle_idx = INT_MAX; 74 75 trace_sched_cpu_util(i); 76 77 if (!cpu_online(i) || cpu_isolated(i)) //cpu處於非online,或者isolate狀態,則直接不考慮 78 continue; 79 80 if (isolated_candidate == -1) 81 isolated_candidate = i; 82 83 /* 84 * This CPU is the target of an active migration that's 85 * yet to complete. Avoid placing another task on it. 86 * See check_for_migration() 87 */ 88 if (is_reserved(i)) //已經有task要遷移到上面,但是還沒有遷移完成。所以這樣的cpu不考慮 89 continue; 90 91 if (sched_cpu_high_irqload(i)) //高irq load的cpu不考慮。irq load可以參考之前WALT文章:https://www.cnblogs.com/lingjiajun/p/12317090.html 92 continue; 93 94 if (fbt_env->skip_cpu == i) //當前活動的cpu是否有很多event一起wakeup,如果有,那麼也不考慮該cpu 95 continue; 96 97 /* 98 * p's blocked utilization is still accounted for on prev_cpu 99 * so prev_cpu will receive a negative bias due to the double 100 * accounting. However, the blocked utilization may be zero. 101 */ 102 wake_util = cpu_util_without(i, p); //計算沒有除了p以外的cpu_util(p不在該cpu rq的情況下,實際就是當前cpu_util) 103 new_util = wake_util + task_util_est(p); //計算cpu_util + p的task_util(p的task_util就是walt統計的demand_scaled) 104 spare_wake_cap = capacity_orig - wake_util; //剩餘的capacity = capacity_orig - p以外的cpu_util 105 106 if (spare_wake_cap > most_spare_wake_cap) { 107 most_spare_wake_cap = spare_wake_cap; //在循環中,找到有剩餘capacity最多(最空閑)的cpu = i,並保存剩餘的capacity 108 most_spare_cap_cpu = i; 109 } 110 111 if (per_task_boost(cpu_rq(i)->curr) == //cpu【i】當前running_task的task_boost == TASK_BOOST_STRICT_MAX,那麼不適合作為tager_cpu 112 TASK_BOOST_STRICT_MAX) 113 continue; 114 /* 115 * Cumulative demand may already be accounting for the 116 * task. If so, add just the boost-utilization to 117 * the cumulative demand of the cpu. 118 */ 119 if (task_in_cum_window_demand(cpu_rq(i), p)) //計算新的cpu【i】的cpu_util_cum = cpu_util_cum + p的boosted_task_util 120 new_util_cuml = cpu_util_cum(i, 0) + //特別地,如果p已經在cpu【i】的rq中,或者p的部分demand被統計在了walt中。那麼防止統計2次,所以要減去p的task_util(denamd_scaled) 121 min_util - task_util(p); 122 else 123 new_util_cuml = cpu_util_cum(i, 0) + min_util; 124 125 /* 126 * Ensure minimum capacity to grant the required boost. 127 * The target CPU can be already at a capacity level higher 128 * than the one required to boost the task. 129 */ 130 new_util = max(min_util, new_util); //取 p的booted_task_util、加入p之後的cpu_util,之間的較大值 131 if (new_util > capacity_orig) //與capacity_orig比較,大於capacity_orig的情況下,不適合作為target_cpu 132 continue; 133 134 /* 135 * Pre-compute the maximum possible capacity we expect 136 * to have available on this CPU once the task is 137 * enqueued here. 138 */ 139 spare_cap = capacity_orig - new_util; //預計算當p遷移到cpu【i】上后,剩餘的可能最大capacity 140 141 if (idle_cpu(i)) //判斷當前cpu【i】是否處於idle,並獲取idle index(idle的深度) 142 idle_idx = idle_get_state_idx(cpu_rq(i)); 143 144 145 /* 146 * Case A) Latency sensitive tasks 147 * 148 * Unconditionally favoring tasks that prefer idle CPU to 149 * improve latency. 150 * 151 * Looking for: 152 * - an idle CPU, whatever its idle_state is, since 153 * the first CPUs we explore are more likely to be 154 * reserved for latency sensitive tasks. 155 * - a non idle CPU where the task fits in its current 156 * capacity and has the maximum spare capacity. 157 * - a non idle CPU with lower contention from other 158 * tasks and running at the lowest possible OPP. 159 * 160 * The last two goals tries to favor a non idle CPU 161 * where the task can run as if it is "almost alone". 162 * A maximum spare capacity CPU is favoured since 163 * the task already fits into that CPU's capacity 164 * without waiting for an OPP chance. 165 * 166 * The following code path is the only one in the CPUs 167 * exploration loop which is always used by 168 * prefer_idle tasks. It exits the loop with wither a 169 * best_active_cpu or a target_cpu which should 170 * represent an optimal choice for latency sensitive 171 * tasks. 172 */ 173 if (prefer_idle) { //對lantency有要求的task 174 /* 175 * Case A.1: IDLE CPU 176 * Return the best IDLE CPU we find: 177 * - for boosted tasks: the CPU with the highest 178 * performance (i.e. biggest capacity_orig) 179 * - for !boosted tasks: the most energy 180 * efficient CPU (i.e. smallest capacity_orig) 181 */ 182 if (idle_cpu(i)) { //如果cpu【i】是idle的 183 if (boosted && 184 capacity_orig < target_capacity) //對於boosted task,cpu需要選擇最大capacity_orig,不滿足要continue 185 continue; 186 if (!boosted && 187 capacity_orig > target_capacity) //對於非boosted task,cpu選擇最小capacity_orig,不滿足要continue 188 continue; 189 /* 190 * Minimise value of idle state: skip 191 * deeper idle states and pick the 192 * shallowest. 193 */ 194 if (capacity_orig == target_capacity && 195 sysctl_sched_cstate_aware && 196 idle_idx >= shallowest_idle_cstate) //包括下面的continue,都是為了挑選出處於idle最淺的cpu 197 continue; 198 199 target_capacity = capacity_orig; 200 shallowest_idle_cstate = idle_idx; 201 best_idle_cpu = i; //選出【prefer_idle】best_idle_cpu 202 continue; 203 } 204 if (best_idle_cpu != -1) //過濾上面已經找到best_idle_cpu的情況,不需要走下面流程了 205 continue; 206 207 /* 208 * Case A.2: Target ACTIVE CPU 209 * Favor CPUs with max spare capacity. 210 */ 211 if (capacity_curr > new_util && 212 spare_cap > target_max_spare_cap) { //找到capacity_curr滿足包含進程p的cpu_util,並且找到空閑capacity最多的那個cpu 213 target_max_spare_cap = spare_cap; 214 target_cpu = i; //選出【prefer_idle】target_cpu 215 continue; 216 } 217 if (target_cpu != -1) //如果cpu條件不滿足,則continue,繼續找target_cpu 218 continue; 219 220 221 /* 222 * Case A.3: Backup ACTIVE CPU 223 * Favor CPUs with: 224 * - lower utilization due to other tasks 225 * - lower utilization with the task in 226 */ 227 if (wake_util > min_wake_util) //找出除了p以外的cpu_util最小的cpu 228 continue; 229 230 /* 231 * If utilization is the same between CPUs, 232 * break the ties with WALT's cumulative 233 * demand 234 */ 235 if (new_util == best_active_util && 236 new_util_cuml > best_active_cuml_util) //如果包含p的cpu_util相等,那麼就挑選cpu_util_cum + p的boosted_task_util最小的那個cpu 237 continue; 238 min_wake_util = wake_util; 239 best_active_util = new_util; 240 best_active_cuml_util = new_util_cuml; 241 best_active_cpu = i; //選出【prefer_idle】best_active_cpu 242 continue; 243 } 244 245 /* 246 * Skip processing placement further if we are visiting 247 * cpus with lower capacity than start cpu 248 */ 249 if (capacity_orig < capacity_orig_of(start_cpu)) //cpu【i】capacity_orig < 【start_cpu】capacity_orig的不考慮 250 continue; 251 252 /* 253 * Case B) Non latency sensitive tasks on IDLE CPUs. 254 * 255 * Find an optimal backup IDLE CPU for non latency 256 * sensitive tasks. 257 * 258 * Looking for: 259 * - minimizing the capacity_orig, 260 * i.e. preferring LITTLE CPUs 261 * - favoring shallowest idle states 262 * i.e. avoid to wakeup deep-idle CPUs 263 * 264 * The following code path is used by non latency 265 * sensitive tasks if IDLE CPUs are available. If at 266 * least one of such CPUs are available it sets the 267 * best_idle_cpu to the most suitable idle CPU to be 268 * selected. 269 * 270 * If idle CPUs are available, favour these CPUs to 271 * improve performances by spreading tasks. 272 * Indeed, the energy_diff() computed by the caller67jkkk 273 * will take care to ensure the minimization of energy 274 * consumptions without affecting performance. 275 */ //對latency要求不高的task,並要求idle cpu作為target的情況 276 if (idle_cpu(i)) { //判斷cpu【i】是否idle 277 /* 278 * Prefer shallowest over deeper idle state cpu, 279 * of same capacity cpus. 280 */ 281 if (capacity_orig == target_capacity && //選出capacity相同情況下,idle最淺的cpu 282 sysctl_sched_cstate_aware && 283 idle_idx > shallowest_idle_cstate) 284 continue; 285 286 if (shallowest_idle_cstate == idle_idx && 287 target_capacity == capacity_orig && 288 (best_idle_cpu == prev_cpu || 289 (i != prev_cpu && 290 new_util_cuml > best_idle_cuml_util))) //best_idle_cpu非prev_cpu,並且挑選cpu_util_cum + p的boosted_task_util最小的 291 continue; 292 293 target_capacity = capacity_orig; 294 shallowest_idle_cstate = idle_idx; 295 best_idle_cuml_util = new_util_cuml; 296 best_idle_cpu = i; //選出【normal-idle】best_idle_cpu 297 continue; 298 } 299 300 /* 301 * Consider only idle CPUs for active migration. 302 */ 303 if (p->state == TASK_RUNNING) //task p正在運行說明是misfit task,只考慮idle cpu作為target,不進行下面流程 304 continue; 305 306 /* 307 * Case C) Non latency sensitive tasks on ACTIVE CPUs. 308 * 309 * Pack tasks in the most energy efficient capacities. 310 * 311 * This task packing strategy prefers more energy 312 * efficient CPUs (i.e. pack on smaller maximum 313 * capacity CPUs) while also trying to spread tasks to 314 * run them all at the lower OPP. 315 * 316 * This assumes for example that it's more energy 317 * efficient to run two tasks on two CPUs at a lower 318 * OPP than packing both on a single CPU but running 319 * that CPU at an higher OPP. 320 * 321 * Thus, this case keep track of the CPU with the 322 * smallest maximum capacity and highest spare maximum 323 * capacity. 324 */ //對latency要求不高,並需要ACTIVE cpu作為target的情況 325 326 /* Favor CPUs with maximum spare capacity */ 327 if (spare_cap < target_max_spare_cap) //找到遷移p之後,剩餘capacity最多的cpu 328 continue; 329 330 target_max_spare_cap = spare_cap; 331 target_capacity = capacity_orig; 332 target_cpu = i; //找出【normal-ACTIVe】的target_cpu 333 } //到此就是一個調度組(cluster)內cpu的循環查找 334 335 next_group_higher_cap = (capacity_orig_of(group_first_cpu(sg)) < 336 capacity_orig_of(group_first_cpu(sg->next))); //嘗試查找下一個capacity更大的big cluster 337 338 /* 339 * If we've found a cpu, but the boost is ON_ALL we continue 340 * visiting other clusters. If the boost is ON_BIG we visit 341 * next cluster if they are higher in capacity. If we are 342 * not in any kind of boost, we break. 343 * 344 * And always visit higher capacity group, if solo cpu group 345 * is not in idle. 346 */ 347 if (!prefer_idle && !boosted && //上面找到cpu但是boost=ON_ALL,那麼還要查找其他cluster 348 ((target_cpu != -1 && (sg->group_weight > 1 || //上面找到cpu但是boost=ON_BIG,那麼還要在capacity更大的cluster中查找 349 !next_group_higher_cap)) || //上面找到了cpu,並且不在任何boost。那麼break 350 best_idle_cpu != -1) && //如果上面group中,沒有cpu是idle,那麼always在capacity更大的cluster中查找 351 (fbt_env->placement_boost == SCHED_BOOST_NONE || 352 !is_full_throttle_boost() || 353 (fbt_env->placement_boost == SCHED_BOOST_ON_BIG && 354 !next_group_higher_cap))) 355 break; 356 357 /* 358 * if we are in prefer_idle and have found an idle cpu, 359 * break from searching more groups based on the stune.boost and 360 * group cpu capacity. For !prefer_idle && boosted case, don't 361 * iterate lower capacity CPUs unless the task can't be 362 * accommodated in the higher capacity CPUs. 363 */ 364 if ((prefer_idle && best_idle_cpu != -1) || //如果設置了prefer_idle,並且找到了一個idle cpu;根據schedtune是否打開boost和是否有更大capacity的cluster進行判斷是否break 365 (boosted && (best_idle_cpu != -1 || target_cpu != -1 || //沒有prefer_idle,但是打開boost的情況,除非high capacity的cpu不能接受task,否則不用再遍歷low capacity的cpu 366 (fbt_env->strict_max && most_spare_cap_cpu != -1)))) { 367 if (boosted) { 368 if (!next_group_higher_cap) 369 break; 370 } else { 371 if (next_group_higher_cap) 372 break; 373 } 374 } 375 376 } while (sg = sg->next, sg != start_sd->groups); 377 378 adjust_cpus_for_packing(p, &target_cpu, &best_idle_cpu, //計算將task放在target_cpu時,在考慮20%的余量,和sched_load_boost之後,看capacity是否滿足target_cpu當前freq的capacity 379 shallowest_idle_cstate, //另外檢查rtg,看是否不考慮idle cpu 380 fbt_env, boosted); 381 382 /* 383 * For non latency sensitive tasks, cases B and C in the previous loop, 384 * we pick the best IDLE CPU only if we was not able to find a target 385 * ACTIVE CPU. //latency要求不高的task選擇cpu優先級:ACTIVE cpu > idle cpu;沒有ACITVE,則選idle cpu 386 * 387 * Policies priorities: 388 * 389 * - prefer_idle tasks: //prefer_idle的task選擇cpu優先級:idle cpu > ACTIVE cpu(包含task之後又更多spare capacity) > ACTIVE cpu(更小cpu_util+boosted_task_util) 390 * 391 * a) IDLE CPU available: best_idle_cpu 392 * b) ACTIVE CPU where task fits and has the bigger maximum spare 393 * capacity (i.e. target_cpu) 394 * c) ACTIVE CPU with less contention due to other tasks 395 * (i.e. best_active_cpu) 396 * 397 * - NON prefer_idle tasks: //非prefer_idle的task選擇cpu優先級:ACTIVE cpu > idle cpu 398 * 399 * a) ACTIVE CPU: target_cpu 400 * b) IDLE CPU: best_idle_cpu 401 */ 402 403 if (prefer_idle && (best_idle_cpu != -1)) { //prefer_idle的task,直接選擇best_idle_cpu作為target 404 target_cpu = best_idle_cpu; 405 goto target; 406 } 407 408 if (target_cpu == -1) //假如target沒有找到,那麼重新找target: 409 target_cpu = prefer_idle 410 ? best_active_cpu //1、prefer_idle的task選擇best_active_cpu; 411 : best_idle_cpu; //2、而非prefer_idle的task選擇best_idle_cpu 412 else 413 backup_cpu = prefer_idle //假如找到了target,那麼再選backup_cpu: 414 ? best_active_cpu //1、prefer_idle的task選擇 best_active_cpu 415 : best_idle_cpu; //2、非prefer_idle的task選擇 best_idle_cpu 416 417 if (target_cpu == -1 && most_spare_cap_cpu != -1 && 418 /* ensure we use active cpu for active migration */ //active migration(misfit task遷移)情況只選擇active cpu 419 !(p->state == TASK_RUNNING && !idle_cpu(most_spare_cap_cpu))) 420 target_cpu = most_spare_cap_cpu; 421 422 if (target_cpu == -1 && isolated_candidate != -1 && //假如沒有找到target_cpu,prev_cpu又處於isolated,而task允許的所有cpu中有online並且unisolated的 423 cpu_isolated(prev_cpu)) 424 target_cpu = isolated_candidate; //那麼就選擇最後一個online並unisolated的cpu作為target 425 426 if (backup_cpu >= 0) 427 cpumask_set_cpu(backup_cpu, cpus); //將backup_cpu存放進cpus中 428 if (target_cpu >= 0) { 429 target: 430 cpumask_set_cpu(target_cpu, cpus); //將找出的target cpu存放進cpus中 431 } 432 433 out: 434 trace_sched_find_best_target(p, prefer_idle, min_util, start_cpu, 435 best_idle_cpu, best_active_cpu, 436 most_spare_cap_cpu, 437 target_cpu, backup_cpu); 438 }
(2)計算energy
/* * compute_energy(): Estimates the energy that would be consumed if @p was * migrated to @dst_cpu. compute_energy() predicts what will be the utilization * landscape of the * CPUs after the task migration, and uses the Energy Model * to compute what would be the energy if we decided to actually migrate that * task. */ static long compute_energy(struct task_struct *p, int dst_cpu, struct perf_domain *pd) { long util, max_util, sum_util, energy = 0; int cpu; for (; pd; pd = pd->next) { max_util = sum_util = 0; /* * The capacity state of CPUs of the current rd can be driven by * CPUs of another rd if they belong to the same performance * domain. So, account for the utilization of these CPUs too * by masking pd with cpu_online_mask instead of the rd span. * * If an entire performance domain is outside of the current rd, * it will not appear in its pd list and will not be accounted * by compute_energy(). */ for_each_cpu_and(cpu, perf_domain_span(pd), cpu_online_mask) { //在perf domain的cpu中找出online的 #ifdef CONFIG_SCHED_WALT util = cpu_util_next_walt(cpu, p, dst_cpu); //計算遷移task p之後,每個cpu的util情況 #else util = cpu_util_next(cpu, p, dst_cpu); util += cpu_util_rt(cpu_rq(cpu)); util = schedutil_energy_util(cpu, util); #endif max_util = max(util, max_util); //找到perf domain中cpu util最大的值(同perf domain,即cluster,最大的util決定了freq的設定) sum_util += util; //統計遷移之後,perf domain內的總util } energy += em_pd_energy(pd->em_pd, max_util, sum_util); //計算perf domain的energy,並累計大小cluster的energy,就是整個系統energy } return energy; }
獲取perf domain內的energy,在其中有2個重要的結構體:
/** * em_cap_state - Capacity state of a performance domain * @frequency: The CPU frequency in KHz, for consistency with CPUFreq * @power: The power consumed by 1 CPU at this level, in milli-watts * @cost: The cost coefficient associated with this level, used during * energy calculation. Equal to: power * max_frequency / frequency */ struct em_cap_state { unsigned long frequency; unsigned long power; unsigned long cost; }; /** * em_perf_domain - Performance domain * @table: List of capacity states, in ascending order * @nr_cap_states: Number of capacity states * @cpus: Cpumask covering the CPUs of the domain * * A "performance domain" represents a group of CPUs whose performance is * scaled together. All CPUs of a performance domain must have the same * micro-architecture. Performance domains often have a 1-to-1 mapping with * CPUFreq policies. */ struct em_perf_domain { struct em_cap_state *table; int nr_cap_states; unsigned long cpus[0]; };
em_pd_energy函數可以得到perf domain的energy。
/** * em_pd_energy() - Estimates the energy consumed by the CPUs of a perf. domain * @pd : performance domain for which energy has to be estimated * @max_util : highest utilization among CPUs of the domain * @sum_util : sum of the utilization of all CPUs in the domain * * Return: the sum of the energy consumed by the CPUs of the domain assuming * a capacity state satisfying the max utilization of the domain. */ static inline unsigned long em_pd_energy(struct em_perf_domain *pd, unsigned long max_util, unsigned long sum_util) { unsigned long freq, scale_cpu; struct em_cap_state *cs; int i, cpu; if (!sum_util) return 0; /* * In order to predict the capacity state, map the utilization of the * most utilized CPU of the performance domain to a requested frequency, * like schedutil. */ cpu = cpumask_first(to_cpumask(pd->cpus)); scale_cpu = arch_scale_cpu_capacity(NULL, cpu); //獲取cpu的max_capacity cs = &pd->table[pd->nr_cap_states - 1]; //獲取capacity state,是為了獲取最大頻點(因為cs的table是升序排列的,所以最後一個配置就是最大的頻點) freq = map_util_freq(max_util, cs->frequency, scale_cpu); //利用上面獲取的最大頻點、max_capacity,根據當前的cpu util映射到當前的cpu freq /* * Find the lowest capacity state of the Energy Model above the * requested frequency. */ for (i = 0; i < pd->nr_cap_states; i++) { //通過循環找到能滿足當前cpu freq的最小的頻點,及其對應的capacity state cs = &pd->table[i]; //同樣因為cs的table是升序排列的,所以遞增找到第一個滿足的,就是滿足條件的最小頻點 if (cs->frequency >= freq) break; } /* * The capacity of a CPU in the domain at that capacity state (cs) * can be computed as: * * cs->freq * scale_cpu * cs->cap = -------------------- (1) * cpu_max_freq * * So, ignoring the costs of idle states (which are not available in * the EM), the energy consumed by this CPU at that capacity state is * estimated as: * * cs->power * cpu_util * cpu_nrg = -------------------- (2) * cs->cap * * since 'cpu_util / cs->cap' represents its percentage of busy time. * * NOTE: Although the result of this computation actually is in * units of power, it can be manipulated as an energy value * over a scheduling period, since it is assumed to be * constant during that interval. * * By injecting (1) in (2), 'cpu_nrg' can be re-expressed as a product * of two terms: * * cs->power * cpu_max_freq cpu_util * cpu_nrg = ------------------------ * --------- (3) * cs->freq scale_cpu * * The first term is static, and is stored in the em_cap_state struct * as 'cs->cost'. * * Since all CPUs of the domain have the same micro-architecture, they * share the same 'cs->cost', and the same CPU capacity. Hence, the * total energy of the domain (which is the simple sum of the energy of * all of its CPUs) can be factorized as: * * cs->cost * \Sum cpu_util * pd_nrg = ------------------------ (4) * scale_cpu */ return cs->cost * sum_util / scale_cpu; //通過上面的註釋以及公式,推導出energy計算公式,並計算出perf doamin的總energy }
總結
1、find_best_target()函數主要是根據當前情況,找到task遷移的candidate cpu(target_cpu、backup cpu、prev_cpu)
具體邏輯:
prefer_idle:
best_idle_cpu:必須選擇idle狀態的cpu
—【task打開boost,選大核cpu】 && 【idle state最淺】
—【task沒有打開boost,選小核cpu】 && 【idle state最淺】
target_cpu:必選選擇ACTIVE狀態的cpu
—【當前freq的cpu_capacity > 遷移task后的cpu_util】 && 【遷移task之後,剩餘capacity最多的cpu】
best_active_cpu:必選選擇ACTIVE狀態的cpu
—【當前cpu_util更小的cpu】 && 【遷移task之後的cpu_util相等的話,選擇cpu_util_cum + boosted_task_util】
normal:
該cpu的capacity_orig > start_cpu的capacity_orig(只會往更大的cluster中尋找)
best_idle_cpu:必須選擇idle狀態的cpu
—【capacity相同情況下,idle最淺的cpu】 && 【選擇cpu_util_cum + boosted_task_util中最小的】 && 【不能是prev_cpu】
非misfit task遷移的情況下,還要選出target_cpu
target_cpu:必選選擇ACTIVE狀態的cpu
—【遷移task之後,剩餘capacity最多的cpu】】
2、在find_energy_efficient_cpu()後半段,計算task遷移到每個candidate cpu后的系統總energy。計算出的最小energy假如比prev_cpu的總energy少6%以上,那麼這個cpu就是best_energy_cpu。
後續:在energy model與energy計算,目前還未弄清楚如何聯繫起來,後續需要找到如何聯繫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
擁有後台管理系統的網站,將擁有強大的資料管理與更新功能,幫助您隨時新增網站的內容並節省網站開發的成本。