java併發編程 –併發問題的根源及主要解決方法
目錄
- 併發問題的根源在哪
- 緩存導致的可見性
- 線程切換帶來的原子性
- 編譯器優化帶來的有序性
- 主要解決辦法
- 避免共享
- Immutability(不變性)
- 管程及其他工具
併發問題的根源在哪
首先,我們要知道併發要解決的是什麼問題?併發要解決的是單進程情況下硬件資源無法充分利用的問題。而造成這一問題的主要原因是CPU-內存-磁盤三者之間速度差異實在太大。如果將CPU的速度比作火箭的速度,那麼內存的速度就像火車,而最慘的磁盤,基本上就相當於人雙腿走路。
這樣造成的一個問題,就是CPU快速執行完它的任務的時候,很長時間都會在等待磁盤或是內存的讀寫。
計算機的發展有一部分就是如何重複利用資源,解決硬件資源之間效率的不平衡,而後就有了多進程,多線程的發展。並且演化出了各種為多進程(線程)服務的東西:
- CPU增加緩存機制,平衡與內存的速度差異
- 增加了多個概念,CPU時間片,程序計數器,線程切換等,用以更好得服務併發場景
- 編譯器的指令優化,希望在內部充分利用硬件資源
但是這樣一來,也會帶來新的併發問題,歸結起來主要有三個。
- 由於緩存導致的可見性問題
- 線程切換帶來的原子性問題
- 編譯器優化帶來的有序性問題
我們分別介紹這幾個:
緩存導致的可見性
CPU為了平衡與內存之間的性能差異,引入了CPU緩存,這樣CPU執行指令修改數據的時候就可以批量直接讀寫CPU緩存的內存,一個階段后再將數據寫回到內存。
但由於現在多核CPU技術的發展,各個線程可能運行在不同CPU核上面,每個CPU核各有各自的CPU緩存。前面說到對變量的修改通常都會先寫入CPU緩存,再寫回內存。這就會出現這樣一種情況,線程1修改了變量A,但此時修改后的變量A只存儲在CPU緩存中。這時候線程B去內存中讀取變量A,依舊只讀取到舊的值,這就是可見性問題。
線程切換帶來的原子性
為了更充分得利用CPU,引入了CPU時間片時間片的概念。進程或線程通過爭用CPU時間片,讓CPU可以更加充分得利用。
比如在進行讀寫磁盤等耗時高的任務時,就可以將寶貴的CPU資源讓出來讓其他線程去獲取CPU並執行任務。
但這樣的切換也會導致問題,那就是會破壞線程某些任務的原子性。比如java中簡單的一條語句count += 1。
映射到CPU指令有三條,讀取count變量指令,變量加1指令,變量寫回指令。雖然在高級語言(java)看來它就是一條指令,但實際上確是三條CPU指令,並且這三條指令的原子性無法保證。也就是說,可能在執行到任意一條指令的時候被打斷,CPU被其他線程搶佔了。而這個期間變量值可能會被修改,這裏就會引發數據不一致的情況了。所以高併發場景下,很多時候都會通過鎖實現原子性。而這個問題也是很多併發問題的源頭。
編譯器優化帶來的有序性
因為現在程序員編寫的都是高級語言,編譯器需要將用戶的代碼轉成CPU可以執行的指令。
同時,由於計算機領域的不斷髮展,編譯器也越來越智能,它會自動對程序員編寫的代碼進行優化,而優化中就有可能出現實際執行代碼順序和編寫的代碼順序不一樣的情況。
而這種破壞程序有序性的行為,在有些時候會出現一些非常微妙且難以察覺的併發編程bug。
舉個簡單的例子,我們常見的單例模式是這樣的:
public class Singleton {
private Singleton() {}
private static Singleton sInstance;
public static Singleton getInstance() {
if (sInstance == null) { //第一次驗證是否為null
synchronized (Singleton.class) { //加鎖
if (sInstance == null) { //第二次驗證是否為null
sInstance = new Singleton(); //創建對象
}
}
}
return sInstance;
}
}
即通過兩段判斷加鎖來保證單例的成功生成,但在極小的概率下,可能會出現異常情況。原因就出現在sInstance = new Singleton();這一行代碼上。這行代碼,我們理解的執行順序應該是這樣:
- 為Singleton象分配一個內存空間。
- 在分配的內存空間實例化對象。
- 把Instance 引用地址指向內存空間。
但在實際編譯的過程中,編譯器有可能會幫我們進行優化,優化完它的順序可能變成如下:
- 為Singleton對象分配一個內存空間。
- 把instance 引用地址指向內存空間。
- 在分配的內存空間實例化對象。
按照優化完的順序,當併發訪問的時候,可能會出現這樣的情況
- A線程進入方法進行第1次instance == null判斷。
- 此時A線程發現instance 為null 所以對Singleton.class加鎖。
- 然後A線程進入方法進行第2次instance == null判斷。
- 然後A線程發現instance 為null,開始進行對象實例化。
- 為對象分配一個內存空間。
6.把Instance 引用地址指向內存空間(而就在這個指令完成后,線程B進入了方法)。 - B線程首先進入方法進行第1次instance == null判斷。
- B線程此時發現instance 不為null ,所以它會直接返回instance (而此時返回的instance 是A線程還沒有初始化完成的對象)
最終線程B拿到的instance 是一個沒有實例化對象的空內存地址,所以導致instance使用的過程中造成程序錯誤。解決辦法很簡單,可以給sInstance對象加上一個關鍵字,volatile,這樣編譯器就不會亂優化,有關volatile的具體內容後續再細說。
主要解決辦法
通過上面的介紹,其實可以歸納無論是CPU緩存,線程切換還是編譯器優化亂序,出現問題的核心都是因為多個線程要併發讀寫某個變量或併發執行某段代碼。那麼我們可以控制,一次只讓一個線程執行變量讀寫就可以了,這就是互斥。
而在某些時候,互斥還不夠,還需要一定的條件。比如一個生產者一個消費者併發,生產者向隊列存東西,消費者向隊列拿東西。那麼生產者寫的時候要保證存的時候隊列不是滿的,消費者要保證拿的時候隊列非空。這種線程與線程間需要通信協作的情況,稱為同步,同步可以說是更複雜的互斥。
既然知道了併發編程的根源以及同步和互斥,那我們來看看有哪些解決的思路。其實一共也就三種:
- 避免共享
- Immutability(不變性)
- 管程及其他工具
下面我們分別說說這三種方案的優缺點
避免共享
我們先來說說避免共享,其實避免共享說是線程本地存儲技術,在java中指的一般就是Threadlocal。ThreadLocal會為每個線程提供一個本地副本,每個線程都只會修改自己的ThreadLocal變量。這樣一來就不會出現共享變量,也就不會出現衝突了。
其實現原理是在ThreadLocal內部維護一個ThreadLocalMap,每次有線程要獲取對應變量的時候,先獲取當前線程,然後根據不同線程取不同的值,典型的以空間換時間。
所以ThreadLocal還是比較適用於需要共享資源,且資源佔用空間不大的情況。比如一些連接的session啊等等。但是這種模式應用場景也較為有限,比如需要同步情況就難以勝任。
Immutability(不變性)
Immutability在函數式中用得比較多,函數式編程的一個主要目的是要寫出無副作用的代碼,有關什麼是無副作用可以參考我以前的文章Scala函數式編程指南(一) 函數式思想介紹。而無副作用的一個主要特點就是變量都是Immutability即不可變的,即創建對象后不會再修改對象,比如scala默認的變量和數據結構都是不可變的。而在java中,不變性變量即通過final修飾的變量,如String,Long,Double等類型都是Immutability的,它們的內部實現都是基於final關鍵字的。
那這又和併發編程有什麼關係呢?其實啊,併發問題很大部分原因就是因為線程切換破壞了原子性,這又導致線程隨意對變量的讀寫破壞了數據的一致性。而不變性就不必擔心這個問題,因為變量都是不變,不可寫只能讀的。在這種編程模式下,你要修改一個變量,那麼只能新生成一個。這樣做的好處很明顯,但壞處也是顯而易見,那就是引入了額外的編程複雜度,喪失了代碼的可讀性和易用性。
因為如此,不變性的併發解決方案其實相對而已沒那麼廣泛,其中比較有代表性的算是Actor併發編程模型,我以前也有討論過,有興趣可以看看Actor模型淺析 一致性和隔離性,這種編程模型和常規併發解決方案有很顯著的差異。按我的了解,Acctor模式多用在分佈式系統的一些協調功能,比如維持集群中多個機器的心跳通信等等。如果在單機併發環境下,還是下面要介紹的管程類工具才是利器。
管程及其他工具
其實最早的操作系統中,解決併發問題用的是信號量,信號量通過兩個原子操作wait(S),和signal(S)(俗稱P,V操作)來實現訪問資源互斥和同步。比如下面這個小例子:
//整型信號量定義
int S;
//P操作
wait(S){
while(S<=0);
S--;
}
//V操作
signal(S){
S++;
}
雖然信號量方便有效,但信號量要對每個共享資源都實現對應的P和V操作,這使得併發編程中可能要出現大量的P,V操作,並且這部分內容難以抽象出來。
為了更好地實現同步互斥,於是就產生了管程(即Monitor,也有翻譯為監視器),值得一提的是,管程也有幾種模型,分別是:Hasen模型,Hoare模型和MESA模型。其中MESA模型應用最廣泛,java也是參考自MESA模型。這裏簡單介紹下管程的理論知識,這部分內容參考自進程同步機制—–為進程併發執行保駕護航,希望了解更多管程理論知識的童鞋可以看看。
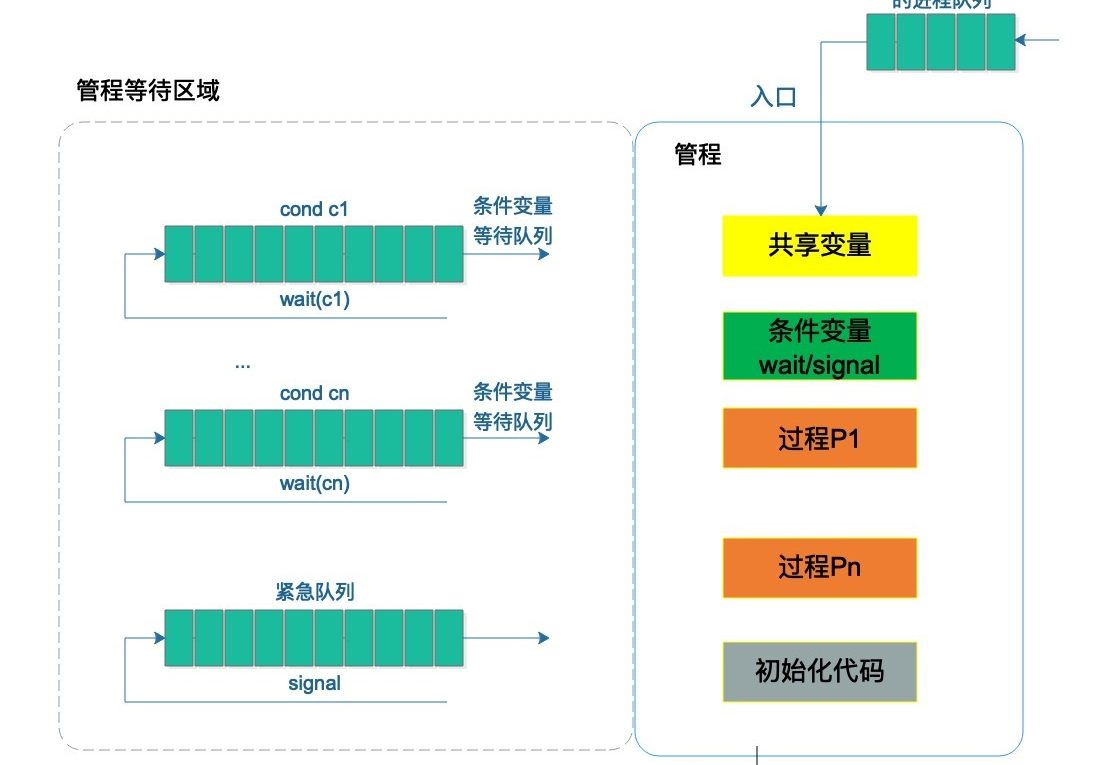
我們來通過一個經典的生產-消費隊列來解釋,如下圖
我們先解釋下圖中右半部分的內容,右上角有一個等待調用的線程隊列,管程中每次只能有一個線程在執行任務,所以多個任務需要等待。然後是各個名詞的意思,生產-消費需要往隊列寫入和取出東西,這裏的隊列就是共享變量,對共享資源進行操作稱之為過程(入隊和出隊兩個過程)。而向隊列寫入和取出是有條件的,寫入的時候隊列必須是非滿的,取出的時候隊列必須是非空的,這兩個條件被稱為條件變量。
然後再來看看左半部分的內容,假設線程T1讀取共享變量(即隊列),此時發現隊列為空(條件變量之一),那麼T1此時需要等待,去哪裡等呢?去條件變量隊列不能為空對應的隊列中去等待。此時另一個線程T2向共享變量隊列寫數據,通過了條件變量隊列不能滿,那麼寫完后就會通知線程T1。但因為管程的限制,管程中只能有一個線程在執行,所以T1線程不能立即執行,它會回到右上角的線程等待隊列等待(不同的管程模型在這裡是有分歧的,比如Hasen模型是立即中斷T2線程讓隊列中下一個線程執行)。
解釋完這個圖,管程的概念也就呼之欲出了,
hansen對管程的定義如下:一個管程定義了一個數據結構和能力為併發進程所執行(在該數據結構上)的一組操作,這組操作能同步進程和改變管程中的數據。
本質上,管程是對共享資源以及對共享資源的操作抽象成變量和方法,要操作共享變量僅能通過管程提供的方法(比如上面的入隊和出隊)間接訪問。所以你會發現管程其實和面向對象的理念是十分相近的,在java中,主要提供了低層次了synchronized關鍵字和wait(),notify()等方法。同時還提供了高層次的ReenTrantLock和Condition來實現管程模型。
以上~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化