多線程高併發編程(12) — 阻塞算法實現ArrayBlockingQueue源碼分析
一.前言
前文探究了非阻塞算法的實現ConcurrentLinkedQueue安全隊列,也說明了阻塞算法實現的兩種方式,使用一把鎖(出隊和入隊同一把鎖ArrayBlockingQueue)和兩把鎖(出隊和入隊各一把鎖LinkedBlockingQueue)來實現,今天來探究下ArrayBlockingQueue。
ArrayBlockingQueue是一個阻塞隊列,底層使用數組結構實現,按照先進先出(FIFO)的原則對元素進行排序。
ArrayBlockingQueue是一個線程安全的集合,通過ReentrantLock鎖來實現,在併發情況下可以保證數據的一致性。
此外,ArrayBlockingQueue的容量是有限的,數組的大小在初始化時就固定了,不會隨着隊列元素的增加而出現擴容的情況,也就是說ArrayBlockingQueue是一個“有界緩存區”。
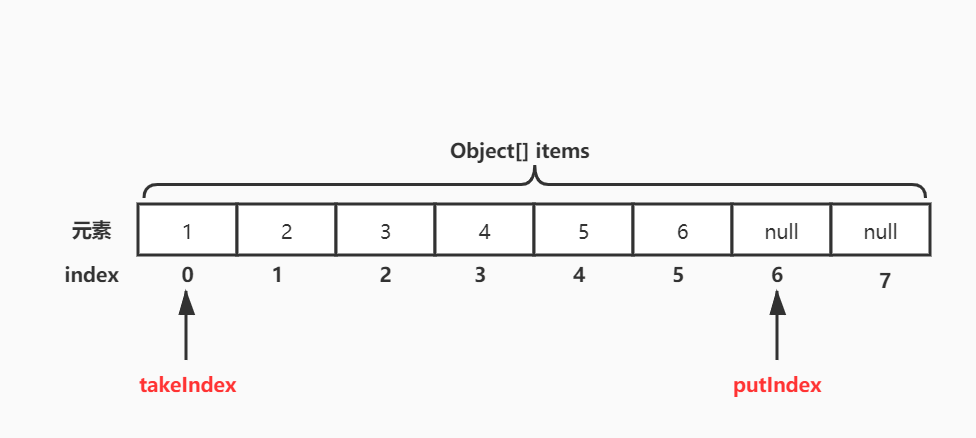
從下圖可以看出,ArrayBlockingQueue是使用一個數組存儲元素的,當向隊列插入元素時,首先會插入到數組下標索引為6的位置,再有新元素進來時插入到索引為7的位置,依次類推,如果滿了就不會再插入。
當元素出隊時,先移除索引為2的元素3,與入隊一樣,依次類推,移除索引3、4、5…上的元素。這也形成了“先進先出”。
二.源碼解析
-
構造方法
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { //隊列實現:數組 final Object[] items; //當讀取元素時數組的下標(下一個被取出元素的索引) int takeIndex; //添加元素時數組的下標 (下一個被添加元素的索引) int putIndex; //隊列中元素個數: int count; //可重入鎖: final ReentrantLock lock; //入隊操作時是否讓線程等待 private final Condition notEmpty; //出隊操作時是否讓線程等待 private final Condition notFull; /** * 初始化隊列容量構造:由於公平鎖會降低隊列的性能,因而使用非公平鎖(默認)。 */ public ArrayBlockingQueue(int capacity) { this(capacity, false); } //帶初始容量大小和公平鎖隊列(公平鎖通過ReentrantLock實現): public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } }
-
在多線程中,默認不保證線程公平的訪問隊列;
-
在ArrayBlockingQueue中為了保證數據的安全,使用了ReentrantLock鎖。由於鎖的引入,導致了線程之間的競爭。當有一個線程獲取到鎖時,其餘線程處於等待狀態。當鎖被釋放時,所有等待線程為奪鎖而競爭;
-
鎖有公平鎖和非公平鎖:
-
公平鎖:等待的線程在獲取鎖而競爭時,按照等待的先後順序FIFO進行獲取操作;公平鎖可以應用在比如併發下的日誌輸出隊列中,保證了日誌輸出的順序完整性;
-
優點:等待鎖的線程不會餓死,和非公平鎖相比,在獲得鎖和保證鎖分配的均衡性差異較小;
-
缺點:使用公平鎖的程序在多線程訪問時表現為很低的吞吐量(即速度很慢),等待隊列中除第一個線程以外的所有線程都會阻塞,CPU喚醒阻塞線程的開銷比非公平鎖的大;公平鎖不能保證線程調度的公平性,因此,使用公平鎖的眾多線程中的一員可能獲得多倍的成功機會,這種情況發生在其他活動線程沒有被處理並且目前並未持有鎖時【ReentrantLock源碼對公平鎖的定義】;
Note however, that fairness of locks does not guarantee fairness of thread scheduling. Thus, one of many threads using a fair lock may obtain it multiple times in succession while other active threads are not progressing and not currently holding the lock.
-
上面這句話有重入鎖的概念,一個線程可以在已經獲取鎖的情況下再次進入獲取到鎖,不需要競爭;同時,如果一個線程獲取到了鎖,然後釋放,在其他線程來獲取之前再次是可以獲取到鎖的。
A: Request Lock -> Release Lock -> Request Lock Again (Succeeds) B: Request Lock (Denied)... ----------------------- Time --------------------------------->
-
-
-
非公平鎖:在獲取鎖時,無論是先等待還是后等待的線程,均有可能獲取到鎖。即根據搶佔機制,是隨機獲取鎖的,和公平鎖不一樣的是先來的不一定能獲取到鎖,有可能一直拿不到鎖,這樣會造成“飢餓”現象;
-
優點:非公平鎖性能高於公平鎖性能。首先,在恢復一個被掛起的線程與該線程真正運行之間存在着嚴重的延遲,而且,非公平鎖更能充分的利用CPU的時間片,盡量減少CPU空閑的狀態時間;即可以減少喚起線程的開銷,整體的吞吐效率高,因為線程有幾率不阻塞直接獲取到鎖,CPU不必喚醒其他所有線程;
-
缺點:處於等待隊列中的線程可能會餓死或者等很久才會獲得鎖;
-
-
產生“飢餓”的原因:
-
高優先級吞噬所有低優先級的CPU時間片,優先級越高,就會獲得越高的CPU執行機會; —> 使用默認的優先級;
-
線程被永久阻塞在一個等待進入同步塊synchronized的狀態(長時間執行) ,同時synchronized並不保障等待線程的順序(鎖釋放后,隨機競爭,由OS調度),這會存在一個可能是某個線程總是搶鎖搶不到導致一直等待狀態 —> 避免持有鎖的線程長時間執行、使用显示lock來代替synchronized;
synchronized(obj) { while (true) { // .... infinite loop }
-
等待的線程永遠不被喚醒:如果多個線程處在wait方法執行上,而對其調用notify方法不會保證哪一個線程會獲得喚醒,喚醒是無序的,跟VM/OS調度有關,甚至底層是隨機選取一個或是隊列中的第一個,任何線程都有可能處於繼續等待的狀態,因此存在這樣一個風險,即一個等待線程從來得不到喚醒,因為其他等待線程總是能被獲得喚醒 —> 使用显示lock來代替synchronized;
-
-
比如ReentrantLock:
-
在公平鎖中,如果有另一個線程持有鎖或者有其他線程在等待隊列中等待這個鎖,那麼新發出的請求的線程將被放入到隊列中;
-
非公平鎖中, 根據搶佔機制,擁有鎖的線程在釋放鎖資源的時候, 新發出請求的線程可以和等待隊列中的第一個線程競爭鎖資源, 新線程競爭失敗才放入隊列中,但是已經進入等待隊列的線程, 依然是按照先進先出的順序獲取鎖資源;
-
-
-
-
入隊:有阻塞式和非阻塞式
-
阻塞式:當隊列中的元素已滿時,則會將此線程停止,讓其處於等待狀態,直到隊列中有空餘位置產生
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly();//獲取鎖 try { //隊列中元素 == 數組長度(隊列滿了),則線程等待 while (count == items.length) notFull.await(); enqueue(e);//元素加入隊列 } finally { lock.unlock();//釋放鎖 } }
-
lockInterruptibly:
-
如果當前線程未被中斷,則獲取鎖。
-
如果該鎖沒有被另一個線程保持,則獲取該鎖並立即返回,將鎖的保持計數設置為 1。
-
如果當前線程已經保持此鎖,則將保持計數加 1,並且該方法立即返回。
-
如果鎖被另一個線程保持,則出於線程調度目的,禁用當前線程,並且在發生以下兩種情況之一以前,該線程將一直處於休眠狀態:1)鎖由當前線程獲得;2)其他某個線程中斷當前線程
-
-
-
非阻塞式:當隊列中的元素已滿時,並不會阻塞此線程的操作,而是讓其返回又或者是拋出異常
public boolean add(E e) { return super.add(e);// AbstractQueue.add } public boolean add(E e) { if (offer(e))//調用實現接口 return true; else throw new IllegalStateException("Queue full"); } public boolean offer(E e) { checkNotNull(e);//檢測是否有空指針異常 final ReentrantLock lock = this.lock;//獲得鎖對象 lock.lock();//加鎖 try { //如果隊列滿了,返回false if (count == items.length) return false; else { //元素加入隊列 enqueue(e); return true; } } finally { lock.unlock();//釋放鎖 } } private void enqueue(E x) { // assert lock.getHoldCount() == 1; // assert items[putIndex] == null; //獲得數組 final Object[] items = this.items; //槽位填充元素 items[putIndex] = x; //獲得下一個被添加元素的索引,如果值等於數組長度,表示到達尾部了,需要從頭開始填充 if (++putIndex == items.length) putIndex = 0; count++;//數量+1 notEmpty.signal();//喚醒出隊上的等待線程,表示有元素可以消費了 }
-
enqueue中++putIndex == items.length,putIndex=0:這是因為當前隊列執行元素出隊時總是從隊列頭部獲取,而添加元素的索引從隊列尾部獲取所以當隊列索引(從0開始)與數組長度相等時,下次我們就需要從數組頭部開始添加了
-
-
阻塞式和非阻塞式的結合:offer(E e, long timeout, TimeUnit unit),向隊列尾部添加元素,可以設置線程等待時間,如果超過指定時間隊列還是滿的,則返回false;
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException { checkNotNull(e);//檢測是否為空 long nanos = unit.toNanos(timeout);//轉換成超時時間閥值 final ReentrantLock lock = this.lock; lock.lockInterruptibly();//加鎖 try { //隊列是否滿了的判斷 while (count == items.length) { if (nanos <= 0)//等待超時結束返回false return false; nanos = notFull.awaitNanos(nanos);//隊列滿了,等待出隊有空位填充 } enqueue(e);//加入隊列中 return true; } finally { lock.unlock();//釋放鎖 } }
-
-
出隊:同樣有阻塞式和非阻塞式
-
阻塞式:當隊列中的元素已空時,則會將此線程停止,讓其處於等待狀態,直到隊列中有元素插入
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { //隊列為空,進行等待 while (count == 0) notEmpty.await(); return dequeue();//返回出隊元素 } finally { lock.unlock(); } }
-
非阻塞式:當隊列中的元素已滿時,並不會阻塞此線程的操作,而是讓其返回null或元素【裏面的迭代器比較複雜,留待下文探究】
public E poll() { final ReentrantLock lock = this.lock; lock.lock(); try { //隊列為空,返回null,否則返回元素 return (count == 0) ? null : dequeue(); } finally { lock.unlock(); } } private E dequeue() { // assert lock.getHoldCount() == 1; // assert items[takeIndex] != null; final Object[] items = this.items;//獲得隊列 @SuppressWarnings("unchecked") E x = (E) items[takeIndex];//獲得出隊元素 items[takeIndex] = null;//出隊槽位元素置為null //下一個被取出元素的索引+1,如果值等於長度,表示後面沒有元素了,需要從頭開始取出 if (++takeIndex == items.length) takeIndex = 0; count--;//數量-1 if (itrs != null)//迭代器不為空 itrs.elementDequeued();//同時更新迭代器中的元素數據 notFull.signal();//喚醒入隊線程 return x;//返回出隊元素 }
-
阻塞式和非阻塞式的結合:poll(long timeout, TimeUnit unit),出隊獲取元素,可以設置線程等待時間,如果超過指定時間隊列還是空的,則返回null;
public E poll(long timeout, TimeUnit unit) throws InterruptedException { long nanos = unit.toNanos(timeout);//轉換成超時時間閥值 final ReentrantLock lock = this.lock; lock.lockInterruptibly();//加鎖 try { while (count == 0) {//隊列空了,等待 if (nanos <= 0)//超時了返回null return null; nanos = notEmpty.awaitNanos(nanos);//等待入隊填充元素 } return dequeue();//返回出隊元素 } finally { lock.unlock();//釋放鎖 } }
-
-
移除元素remove:
public boolean remove(Object o) { //要移除的元素為空返回false if (o == null) return false; //獲得隊列數組 final Object[] items = this.items; final ReentrantLock lock = this.lock; lock.lock();//加鎖 try { //隊列有元素 if (count > 0) { final int putIndex = this.putIndex;//獲得下一個被添加元素的索引 int i = takeIndex;//下一個被取出元素的索引 do { if (o.equals(items[i])) {//從takeIndex下標開始,找到要被刪除的元素 removeAt(i);//移除 return true; } if (++i == items.length)//下一個被取出元素的索引+1並判斷是否等於隊列長度,如果是,表示需要從頭開始遍歷 i = 0; } while (i != putIndex);//繼續查找,直到找到最後一個元素 } return false; } finally { lock.unlock();//解鎖 } } /** * 根據下標移除元素,那麼會分成兩種情況一個是移除的是隊首元素,一個是移除的是非隊首元素,移除隊首元素,就相當於出隊操作, * 移除非隊首元素那麼中間就有空位了,後面元素需要依次補上,然後如果是隊尾元素,那麼putIndex也就是插入操作的下標也就需要跟着移動。 */ void removeAt(final int removeIndex) { // assert lock.getHoldCount() == 1; // assert items[removeIndex] != null; // assert removeIndex >= 0 && removeIndex < items.length; final Object[] items = this.items;//獲得隊列 if (removeIndex == takeIndex) {//移除的是隊首元素 // removing front item; just advance items[takeIndex] = null;//隊首置為null if (++takeIndex == items.length)//下一個被取出元素的索引+1並判斷是否等於隊列長度 takeIndex = 0; count--;//數量-1 if (itrs != null)//迭代器不為空 itrs.elementDequeued();//更新迭代器元素 } else {//移除的不是隊首元素,而是中間元素 // an "interior" remove // slide over all others up through putIndex. final int putIndex = this.putIndex;//下一個被添加元素的索引 for (int i = removeIndex;;) {//對隊列進行遍歷,因為是隊列中間的值被移除了,所有後面的元素都要挨個遷移 int next = i + 1;//獲取移除元素的下一個坐標 if (next == items.length)//判斷是否等於隊列長度 next = 0; if (next != putIndex) {//獲取移除元素的下一個坐標!=下一個被添加元素的索引,表示移除元素的索引後面有值 items[i] = items[next];//當前要移除的元素置為後面的元素,即對後面的元素往前遷移,覆蓋要移除的元素 i = next;//下一個遷移的索引 } else {//移除的元素是最後一個,後面沒有值了 items[i] = null;//移除元素,直接置為null this.putIndex = i;//更新下一個被添加元素的索引 break;//結束 } } count--;//數量-1 if (itrs != null)//迭代器不為空 itrs.removedAt(removeIndex);//更新迭代器元素 } notFull.signal();//喚醒入隊線程,可以添加元素了 }
-
清空元素clear:用於清空ArrayBlockingQueue,並且會釋放所有等待notFull條件的線程(存放元素的線程)
public void clear() { final Object[] items = this.items;//獲得隊列 final ReentrantLock lock = this.lock; lock.lock(); try { int k = count;//獲取元素數量 if (k > 0) {//有元素,表示隊列不為空 final int putIndex = this.putIndex;//下一個被添加元素的索引 int i = takeIndex;//下一個被取出元素的索引 do { items[i] = null;//對每個有元素的槽位置為null if (++i == items.length) i = 0; } while (i != putIndex);//從有元素的第一個槽位開始遍歷,直到槽位元素為null takeIndex = putIndex;//更新取出和添加的索引 count = 0;//數量更新為0 if (itrs != null)//迭代器不為空 itrs.queueIsEmpty();//更新迭代器為空 //若有等待notFull條件的線程,則逐一喚醒 for (; k > 0 && lock.hasWaiters(notFull); k--) notFull.signal();//喚醒入隊線程,可以添加元素了 } } finally { lock.unlock(); } }
-
offer(E e, long timeout, TimeUnit unit)和poll(long timeout, TimeUnit unit)裏面有awaitNanos,下面探討該功能實現:對當前線程或等待的入/出隊線程進行掛起,如果有入/出隊操作進行了喚醒出/入隊操作,則acquireQueued自旋獲取到鎖,然後出/入隊中的ReentrantLock是重入鎖,可以重入獲取到鎖進行出/入隊操作
AbstractQueuedSynchronizer: //進行超時控制 public final long awaitNanos(long nanosTimeout) throws InterruptedException { //如果當前線程中斷了拋出中斷異常 if (Thread.interrupted()) throw new InterruptedException(); //當前線程加入到Condition隊列中 Node node = addConditionWaiter(); //鎖釋放是否成功:釋放當前線程的lock,從AQS的隊列中移出 int savedState = fullyRelease(node); //到達等待時間點 final long deadline = System.nanoTime() + nanosTimeout; //中斷標識 int interruptMode = 0; //當前節點是否在同步隊列中,否表示不在,進入掛起判斷操作,如果已經在Sync隊列中,則退出循環 //那什麼時候會把當前線程又加入到Sync隊列中呢?當然是調用signal方法的時候,因為這裏需要喚醒之前調用await方法的線程,喚醒之後進行下面的獲取鎖等操作 while (!isOnSyncQueue(node)) { //如果超時了,將線程掛起,然後停止遍歷 if (nanosTimeout <= 0L) { transferAfterCancelledWait(node); break; } //如果等待時間間隔超過了1000,繼續掛起 if (nanosTimeout >= spinForTimeoutThreshold) LockSupport.parkNanos(this, nanosTimeout); //線程中斷了停止遍歷 if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; //獲得剩餘的等待時間間隔 nanosTimeout = deadline - System.nanoTime(); } //結束掛起,acquireQueued自旋對當前線程的隊列出隊進行獲取鎖並返回線程是否中斷 //如果線程被中斷,並且中斷的方式不是拋出異常,則設置中斷後續的處理方式設置為REINTERRUPT if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT;//中斷標識更新為退出等待時重新中斷 if (node.nextWaiter != null)//當前節點後面還有節點,多併發操作了 unlinkCancelledWaiters();//從頭到尾遍歷Condition隊列,移除被cancel的節點 //如果線程已經被中斷,則根據之前獲取的interruptMode的值來判斷是繼續中斷還是拋出異常 if (interruptMode != 0) reportInterruptAfterWait(interruptMode); return deadline - System.nanoTime();//返回剩餘等待時間 }
-
drainTo可以一次性獲取隊列中所有的元素,它減少了鎖定隊列的次數,使用得當在某些場景下對性能有不錯的提升
//最多從此隊列中移除給定數量的可用元素,並將這些元素添加到給定collection中 public int drainTo(Collection<? super E> c) { return drainTo(c, Integer.MAX_VALUE); } public int drainTo(Collection<? super E> c, int maxElements) { checkNotNull(c);//檢查是否為空 if (c == this)//如果集合類型相同拋出參數異常 throw new IllegalArgumentException(); if (maxElements <= 0)//如果給定移除數量小於0,返回0,表示不做移除操作 return 0; final Object[] items = this.items;//獲得隊列 final ReentrantLock lock = this.lock; lock.lock();//加鎖 try { int n = Math.min(maxElements, count);//獲得元素的最小數量 int take = takeIndex;//下一個被取出元素的索引 int i = 0; try { while (i < n) {//遍歷移除和添加 @SuppressWarnings("unchecked") E x = (E) items[take];//獲得移除元素 c.add(x);//元素添加到直到集合中 items[take] = null;//元素原先隊列位置置為null if (++take == items.length)//如果取出索引到達尾部,從頭開始遍歷取出 take = 0; i++;//移除的數量+1,如果達到了移除的最小數量,結束遍歷 } return n;//返回一共移除並添加了多少個元素 } finally { // Restore invariants even if c.add() threw if (i > 0) {//如果有移除操作 count -= i;//隊列元素數量-i takeIndex = take;//重置下一個被取出元素的索引 if (itrs != null) {//迭代器不為空 if (count == 0)//隊列空了 itrs.queueIsEmpty();//迭代器清空 else if (i > take)//說明take中間變成0了,通知itr itrs.takeIndexWrapped(); } //喚醒在因為隊列滿而等待的入隊線程,最多喚醒i個,避免線程被喚醒了因為隊列又滿了而阻塞 for (; i > 0 && lock.hasWaiters(notFull); i--) notFull.signal(); } } } finally { lock.unlock(); } }
三.Logback 框架中異步日誌打印中ArrayBlockingQueue的使用
-
在高併發並且響應時間要求比較小的系統中同步打日誌已經滿足不了需求了,這是因為打日誌本身是需要同步寫磁盤的,會造成 響應時間 增加,如下圖同步日誌打印模型為:
-
異步模型是業務線程把要打印的日誌任務寫入一個隊列后直接返回,然後使用一個線程專門負責從隊列中獲取日誌任務寫入磁盤,其模型具體如下圖:
-
如圖可知其實 logback 的異步日誌模型是一個多生產者單消費者模型,通過使用隊列把同步日誌打印轉換為了異步,業務線程調用異步 appender 只需要把日誌任務放入日誌隊列,日誌線程則負責使用同步的 appender 進行具體的日誌打印到磁盤;
-
-
接下來看看異步日誌打印具體實現,要把同步日誌打印改為異步需要修改 logback 的 xml 配置文件:
<appender name="PROJECT" class="ch.qos.logback.core.FileAppender"> <file>project.log</file> <encoding>UTF-8</encoding> <append>true</append> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- daily rollover --> <fileNamePattern>project.log.%d{yyyy-MM-dd}</fileNamePattern> <!-- keep 7 days' worth of history --> <maxHistory>7</maxHistory> </rollingPolicy> <layout class="ch.qos.logback.classic.PatternLayout"> <pattern> <![CDATA[%n%-4r [%d{yyyy-MM-dd HH:mm:ss}] %X{productionMode} - %X{method} %X{requestURIWithQueryString} [ip=%X{remoteAddr}, ref=%X{referrer}, ua=%X{userAgent}, sid=%X{cookie.JSESSIONID}]%n %-5level %logger{35} - %m%n]]> </pattern> </layout> </appender> <appender name="asyncProject" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0</discardingThreshold> <queueSize>1024</queueSize> <neverBlock>true</neverBlock> <appender-ref ref="PROJECT" /> </appender> <logger name="PROJECT_LOGGER" additivity="false"> <level value="WARN" /> <appender-ref ref="asyncProject" /> </logger>
-
從上面可知 AsyncAppender 是實現異步日誌的關鍵,下面探究它的原理:
-
如上圖可知 AsyncAppender 繼承自 AsyncAppenderBase,其中後者具體實現了異步日誌模型的主要功能,前者只是重寫了其中的一些方法。另外從類圖可知 logback 中的異步日誌隊列是一個阻塞隊列, 後面會知道其實是一個有界阻塞隊列 ArrayBlockingQueue, 其中 queueSize 是有界隊列的元素個數默認為 256;
-
worker則是工作線程,也就是異步打印日誌的消費者線程,aai則是一個appender的裝飾器,裡邊存放的同步日誌的appender,其中appenderCount記錄aai裡邊附加的同步appender的個數(這個和配置文件相對應,一個異步的appender對應一個同步的appender),neverBlock用來指示當同步隊列已滿時是否阻塞打印日誌線程(如果配置neverBlock=true,當隊列滿了之後,後面阻塞的線程想要輸出的消息就直接被丟棄,從而線程不會阻塞),discardingThreshold是一個閾值,當日誌隊列裡邊的空閑元素個數小於該值時,新來的某些級別的日誌就會直接被丟棄。
-
-
接下來看下何時創建的日誌隊列以及何時啟動的消費線程,這需要看下 AsyncAppenderBase 的 start 方法,該方法是在解析完畢配置 AsyncAppenderBase 的 xml 的節點元素后被調用 :
public void start() { if (isStarted()) return; if (appenderCount == 0) { addError("No attached appenders found."); return; } if (queueSize < 1) { addError("Invalid queue size [" + queueSize + "]"); return; } // 創建一個ArrayBlockingQueue阻塞隊列,queueSize默認為256,創建阻塞隊列的原因是:防止生產者過多,造成隊列中元素過多,產生OOM異常 blockingQueue = new ArrayBlockingQueue<E>(queueSize); // 如果discardingThreshold未定義的話,默認為queueSize的1/5 if (discardingThreshold == UNDEFINED) discardingThreshold = queueSize / 5; addInfo("Setting discardingThreshold to " + discardingThreshold); // 將工作線程設置為守護線程,即當jvm停止時,即使隊列中有未處理的元素,也不會在進行處理 worker.setDaemon(true); // 為線程設置name便於調試 worker.setName("AsyncAppender-Worker-" + getName()); // make sure this instance is marked as "started" before staring the worker Thread // 啟動線程 super.start(); worker.start(); }
-
logback 使用的隊列是有界隊列 ArrayBlockingQueue,之所以使用有界隊列是考慮到內存溢出問題,在高併發下寫日誌的 qps 會很高如果設置為無界隊列隊列本身會佔用很大內存,很可能會造成 內存溢出。
-
這裏消費日誌隊列的 worker 線程被設置為了守護線程,意味着當主線程運行結束並且當前沒有用戶線程時候該 worker 線程會隨着 JVM 的退出而終止,而不管日誌隊列裏面是否還有日誌任務未被處理。另外這裏設置了線程的名稱是個很好的習慣,因為這在查找問題的時候很有幫助,根據線程名字就可以定位到是哪個線程。
-
-
既然是有界隊列那麼肯定需要考慮如果隊列滿了,該如何處置,是丟棄老的日誌任務,還是阻塞日誌打印線程直到隊列有空餘元素那?下面看append 方法:
protected void append(E eventObject) { // 判斷隊列中的元素數量是否小於discardingThreshold,如果小於的話,並且日誌等級小於info的話,則直接丟棄這些日誌任務 if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { return; } preprocess(eventObject); // 日誌入隊 put(eventObject); } private boolean isQueueBelowDiscardingThreshold() { return (blockingQueue.remainingCapacity() < discardingThreshold); } // 子類重寫的方法 判斷日誌等級 protected boolean isDiscardable(ILoggingEvent event) { Level level = event.getLevel(); return level.toInt() <= Level.INFO_INT; }
-
日誌入隊put:從下面可知如果 neverBlock 設置為 false(默認為 false)則會調用阻塞隊列的 put 方法,而 put 是阻塞的,也就是說如果當前隊列滿了,如果再企圖調用 put 方法向隊列放入一個元素則調用線程會被阻塞直到隊列有空餘空間。這裡有必要提下其中blockingQueue.put(eventObject)當日誌隊列滿了的時候 put 方法會調用 await() 方法阻塞當前線程,如果其它線程中斷了該線程,那麼該線程會拋出 InterruptedException 異常,那麼當前的日誌任務就會被丟棄了。如果 neverBlock 設置為了 true 則會調用阻塞隊列的 offer 方法,而該方法是非阻塞的,如果當前隊列滿了,則會直接返回,也就是丟棄當前日誌任務。
private void put(E eventObject) { // 判斷是否阻塞(默認為false),則會調用阻塞隊列的put方法 if (neverBlock) { blockingQueue.offer(eventObject); } else { putUninterruptibly(eventObject); } } // 可中斷的阻塞put方法 private void putUninterruptibly(E eventObject) { boolean interrupted = false; try { while (true) { try { blockingQueue.put(eventObject); break; } catch (InterruptedException e) { interrupted = true; } } } finally { if (interrupted) { Thread.currentThread().interrupt(); } } }
-
-
最後看下 addAppender 方法,可以看出,一個異步的appender只能綁定一個同步appender,這個appender會被放入AppenderAttachableImpl的appenderList列表裡邊
public void addAppender(Appender<E> newAppender) { if (appenderCount == 0) { appenderCount++; addInfo("Attaching appender named [" + newAppender.getName() + "] to AsyncAppender."); aai.addAppender(newAppender); } else { addWarn("One and only one appender may be attached to AsyncAppender."); addWarn("Ignoring additional appender named [" + newAppender.getName() + "]"); } }
-
通過上面我們已經分析完了日誌生產線程放入日誌任務到日誌隊列的實現,下面一起來看下消費線程是如何從隊列裏面消費日誌任務並寫入磁盤的,由於消費線程是一個線程,那就從 worker 的 run 方法看起(消費者,將日誌寫入磁盤的線程方法):
class Worker extends Thread { public void run() { AsyncAppenderBase<E> parent = AsyncAppenderBase.this; AppenderAttachableImpl<E> aai = parent.aai; // loop while the parent is started 一直循環知道線程被中斷 while (parent.isStarted()) { try {// 從阻塞隊列中獲取元素,交由給同步的appender將日誌打印到磁盤 E e = parent.blockingQueue.take(); aai.appendLoopOnAppenders(e); } catch (InterruptedException ie) { break; } } addInfo("Worker thread will flush remaining events before exiting. "); //執行到這裏說明該線程被中斷,則把隊列裡邊的剩餘日誌任務刷新到磁盤 for (E e : parent.blockingQueue) { aai.appendLoopOnAppenders(e); parent.blockingQueue.remove(e); } aai.detachAndStopAllAppenders(); } }
-
try邏輯中從日誌隊列使用 take 方法獲取一個日誌任務,如果當前隊列為空則當前線程會阻塞到 take 方法直到隊列不為空才返回,獲取到日誌任務後會調用 AppenderAttachableImpl 的 aai.appendLoopOnAppenders 方法,該方法會循環調用通過 addAppender 注入的同步日誌 appener 具體實現日誌打印到磁盤的任務。
-
四.參考:
- 公平鎖的使用場景:https://stackoverflow.com/questions/26455578/when-to-use-fairness-mode-in-java-concurrency
- 公平鎖和非公平鎖的區別的提問:https://segmentfault.com/q/1010000006439146
- 公平鎖不能保證線程調度的公平性:https://stackoverflow.com/questions/60903107/understanding-fair-reentrantlock-in-java
- logback異步日誌打印中的ArrayBlockingQueue的使用:https://my.oschina.net/u/4410397/blog/3428573
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案