【大廠面試06期】談一談你對Redis持久化的理解?
Redis持久化是面試中經常會問到的問題,這裏主要通過對以下幾個問題進行分析,幫助大家了解Redis持久化的實現原理。
1.Redis持久化是什麼?
2.Redis持久化有哪些策略?各自的實現原理是怎麼樣的?
3.Redis的數據恢復策略是怎麼樣的?
4.Redis持久化策略該如何進行選擇?
1.Redis持久化是什麼?
因為Redis是一個內存數據庫,數據保存在內存中,一旦發生關機或者重啟,內存中的數據都會丟失,所以為了能夠重啟時恢複數據,Redis提供了持久化的機制,正常運行期間根據策略生成持久化文件。在機器重啟后,可以根據根據持久化文件恢復內存中的數據。Redis還為我們提供了持久化的機制。(雖然有主從同步,主機掛掉之後,可以讓從節點成為主節點,但是如果整個機房都發生停電,那麼主節點和從節點內存中的數據都會丟失,所以這也是持久化存在的意義。)
2.Redis持久化有哪些策略?
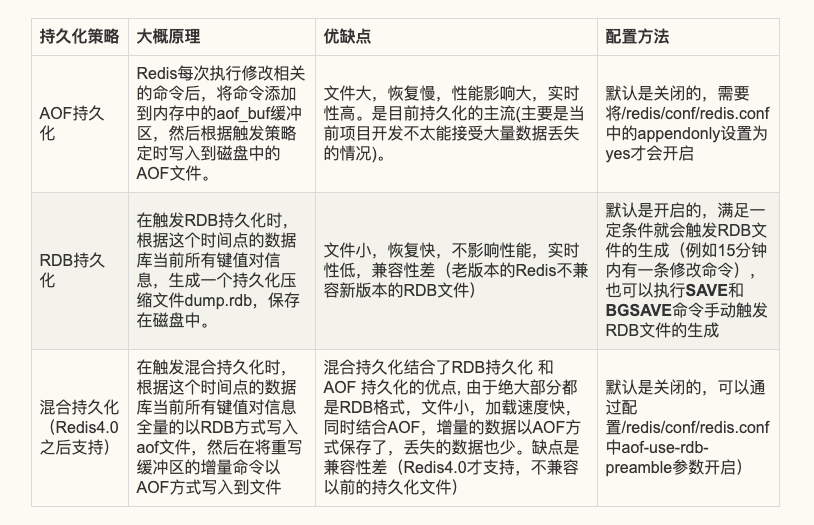
Redis持久化的策略主要有AOF持久化,RDB持久化,混合持久化。這是我自己總結的一個圖:
AOF持久化
執行流程
AOF持久化主要是Redis在修改相關的命令后,將命令添加到aof_buf緩存區的末尾,然後在每次事件循環結束時,
根據appendfsync的配置:
-
appendfsync = always 每條修改命令都會更新到磁盤上的AOF文件, 最多只會丟失當前正在寫入的命令
-
appendfsync = everysec 每秒更新到磁盤上的AOF文件一次, 最多丟失2秒的數據(因為執行fsync命令刷盤也需要時間,下面會解釋)
-
appendfsync = no 不自動更新到磁盤上的AOF文件,由操作系統來決定何時刷盤(linux 貌似大部分默認是 30s)。可能會丟失刷盤之前的寫入數據。
(基於性能考慮一般生產環境的配置都是everysec)
(aof_buf是Redis中的SDS結構,可以理解為是一個字符串,只是對C語言的字符串做了一些優化,每次將新執行的更新命令添加到字符串末尾。)
怎麼防止AOF文件越來越大?
為了防止AOF文件越來越大,可以通過執行BGREWRITEAOF命令,會fork子進程出來,讀取當前數據庫的鍵值對信息,生成所需的寫命令,寫入新的AOF文件。在生成期間,父進程繼續正常處理請求,執行修改命令后,不僅會將命令寫入aof_buf緩衝區,還會寫入重寫aof_buf緩衝區。當新的AOF文件生成完畢后,子進程父進程發送信號,父進程將重寫aof_buf緩衝區的修改命令寫入新的AOF文件,寫入完畢后,對新的AOF文件進行改名,原子地(atomic)地替換舊的AOF文件。
什麼是AOF文件追加阻塞?
修改命令添加到aof_buf之後,如果配置是everysec那麼會每秒執行fsync操作,調用write寫入磁盤一次,但是如果硬盤負載過高,fsync操作可能會超過1s,Redis主線程持續高速向aof_buf寫入命令,硬盤的負載可能會越來越大,IO資源消耗更快,所以Redis的處理邏輯是會對比上次fsync成功的時間,如果超過2s,則主線程阻塞直到fsync同步完成,所以最多可能丟失2s的數據,而不是1s。
RDB持久化
RDB持久化指的是在滿足一定的觸發條件時(在一個的時間間隔內執行修改命令達到一定的數量,或者手動執行SAVE和BGSAVE命令),對這個時間點的數據庫所有鍵值對信息生成一個壓縮文件dump.rdb,然後將舊的刪除,進行替換。
執行流程
實現原理是fork一個子進程,然後對鍵值對進行遍歷,生成rdb文件,在生成過程中,父進程會繼續處理客戶端發送的請求,當父進程要對數據進行修改時,會對相關的內存頁進行拷貝,修改的是拷貝后的數據。(也就是COPY ON WRITE,寫時複製技術,就是當多個調用者同時請求同一個資源,如內存或磁盤上的數據存儲,他們會共用同一個指向資源的指針,指向相同的資源,只有當一個調用者試圖修改資源的內容時,系統才會真正複製一份專用副本給這個調用者,其他調用者還是使用最初的資源,在CopyOnWriteArrayList的實現中,也有用到,添加或者插入一個新元素時過程是,加鎖,對原數組進行複製,然後添加新元素,然後替代舊數組,解鎖)
//CopyOnWriteArrayList的添加元素的方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
混合持久化(Redis4.0+)
執行流程
混合持久化同樣也是通過bgrewriteaof命令完成的,不同的是當開啟混合持久化時,fork出的子進程先將當前內存中的鍵值對信息全量的以RDB方式寫入aof文件,然後在將重寫緩衝區的增量命令以AOF方式寫入到文件,寫入完成后通知主進程更新統計信息,並將新的含有RDB格式和AOF格式的AOF文件替換舊的的AOF文件。簡單的說:新的AOF文件前半段是RDB格式的全量數據後半段是AOF格式的增量數據,如下圖:
3.Redis的數據恢復策略是怎麼樣的?
1.如果配置了混合持久化,那麼根據混合持久化文件進行恢複數據。(Redis4.0+)
2.只配置 AOF ,重啟時加載 AOF 文件恢複數據。
3.同時配置了 RDB 和 AOF ,啟動時只加載 AOF文件恢複數據,如果AOF文件損壞,那麼根據RDB文件恢複數據。
4.只配置 RDB,啟動時加載RDB持久化文件恢複數據。
4.Redis持久化策略該如何進行選擇?
(因為混合持久化是Redis 4.0之後支持的,目前一般生成環境使用的Redis版本可能都還較低,所以這裏的策略選擇主要是針對AOF持久和RDB持久化進行技術選型。)
以下是幾種持久化方案選擇的場景:
1.不需要考慮數據丟失的情況
那麼不需要考慮持久化。
2.單機實例情況下
可以接受丟失十幾分鐘及更長時間的數據,可以選擇RDB持久化,對性能影響小,如果只能接受秒級的數據丟失,只能選擇AOF持久化。
3.在主從環境下
因為主服務器在執行修改命令后,會將命令發送給從服務器,從服務進行執行后,與主服務器保持數據同步,實現數據熱備份,在master宕掉後繼續提供服務。同時也可以進行讀寫分離,分擔Redis的讀請求。
那麼在從服務器進行數據熱備份的情況下,是否還需要持久化呢?
需要持久化,因為不進行持久化,主服務器,從服務器同時出現故障時,會導致數據丟失。(例如:機房全部機器斷電)。如果系統中有自動拉起機制(即檢測到服務停止后重啟該服務)將master自動重啟,由於沒有持久化文件,那麼master重啟后數據是空的,slave同步數據也變成了空的。應盡量避免“自動拉起機制”和“不做持久化”同時出現。
所以一般可以採用以下方案:
主服務器不開啟持久化,使得主服務器性能更好。
從服務器開啟AOF持久化,關閉RDB持久化,並且定時對AOF文件進行備份,以及在凌晨執行bgaofrewrite命令來進行AOF文件重寫,減小AOF文件大小。(當然如果對數據丟失容忍度高也可以開啟RDB持久化,關閉AOF持久化)
4.異地災備
一般性的故障(停電,關機)不會影響到磁盤,但是一些災難性的故障(地震,洪水)會影響到磁盤,所以需要定時把單機上或從服務器上的AOF文件,RDB文件備份到其他地區的機房。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?