上億用戶養大的少女:微軟小冰技術解析

作者李想
編輯 Vincent
12 月 7-8 日在北京舉辦的 ArchSummit 全球架構師峰會上,微軟 Principal Software Manager 李想老師分享了微軟小冰實時感官系統與未來發展趨勢。以下為演講內容,部分有刪減。李想老師首先介紹了什麼是微軟小冰,然後從全雙工語音感官和實時視覺感官這兩個方面,來展望了微軟小冰的未來發展趨勢。什麼是微軟小冰?
目前,微軟小冰已經上線四年了,存在於五個國家、數十款產品之中,有着上億用戶。小冰產品大致可以分為三類:
- ChatBot,即聊天機器人 / 智能語音助手。
- Content Provider,即內容提供商。小冰逐漸有了它自己的社會化角色,不僅可以用非常接近人類的聲音唱歌,還可以寫詩,甚至還可以講兒童故事。
- Solutions,即解決方案。比如,小冰不僅可以在一些新聞客戶端給新聞做一些評價,帶動新聞的整體流量,增加整體活躍性,還可以幫一些商業機構發布商業簡報等等。

小冰的情商
下面主要討論的是小冰的 Chat Bot(聊天機器人)。
四年中,小冰研發團隊在和同行業者朝着相似的目標以截然相反的路線前進。對於智能機器人,傳統想法是要讓人類更加接受它們,就必須讓它們變得很有用,能夠幫助人們去完成一個任務、十個任務,甚至更多。但是,小冰團隊認為,在變得有用的更底端,其實還有一層“情商”,以此為基礎再去一層一層完成任務就會變得更自然。
下面以狼和哈士奇為例來說明一下這個問題。狼其實是一種非常強的生物,但是在以人為本位的群體中,有些種族卻瀕臨滅絕。而哈士奇卻可以整天什麼活都不幹,就能夠很好地融入人類中去。為什麼呢?因為人其實是一種以情感為基礎的生物,我們嘗試賦予與之能夠進行情感交流的對方,予以平等的權利。我們把生物能夠運用的這種權利稱之為情商。以情商為基礎再去完成任務就會變得更加自然。比如哈士奇可以幫你開燈關燈了,你一定會把它捧到天上去。

對於小冰來說,情商高意味着什麼呢?意味着它在聊天過程中很有趣嗎?其實不止如此。情商高,在交互中主要體現為控制全程對話的能力。
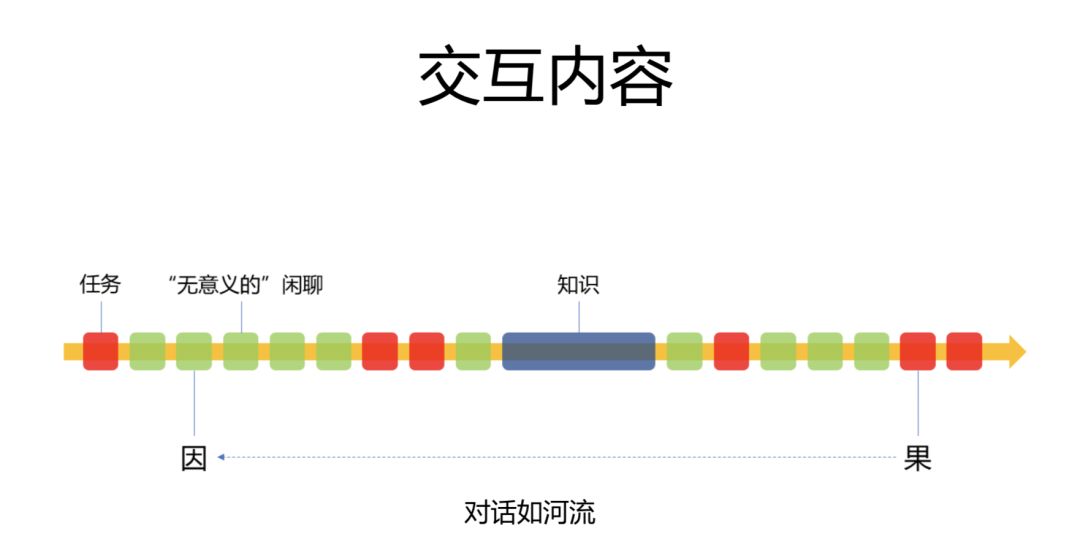
傳統的智能語音助手不會去過度關注對話的全程,而更加關注對話中的每一個細節。它會把每一句話都優化得特別好,甚至把對話形式分為:面向任務型的對話、面向知識型對話、無意義的閑聊。
那麼這真的是無意義的閑聊嗎?也不盡然。
我們知道,小冰背後是大數據,有着 Bing 搜索。從大數據的分析來看,其實人與人的對話 / 人與人工智能的對話,就如同河流一般奔湧向前,任何一句看似無意義的閑聊,都可能在十幾輪甚至幾十輪的迭代之後產生一個非常重要的結果。小冰可以不停地去迭代,去改變對話的走向,去改變對話的長度。它關注的是整個對話的全局,而不是一城一地的得失,正如古人所言,“不謀全局,則不足以謀一隅”,這就是所謂的控制整個對話全程的能力。
全雙工語音交互與實時視覺感官相結合
2017 年,小冰研發團隊發現小冰目前的交互方式已經限制了它控制整個對話全程的能力,就開始嘗試在整個交互方式上進行提升。那麼是怎麼提升的呢?
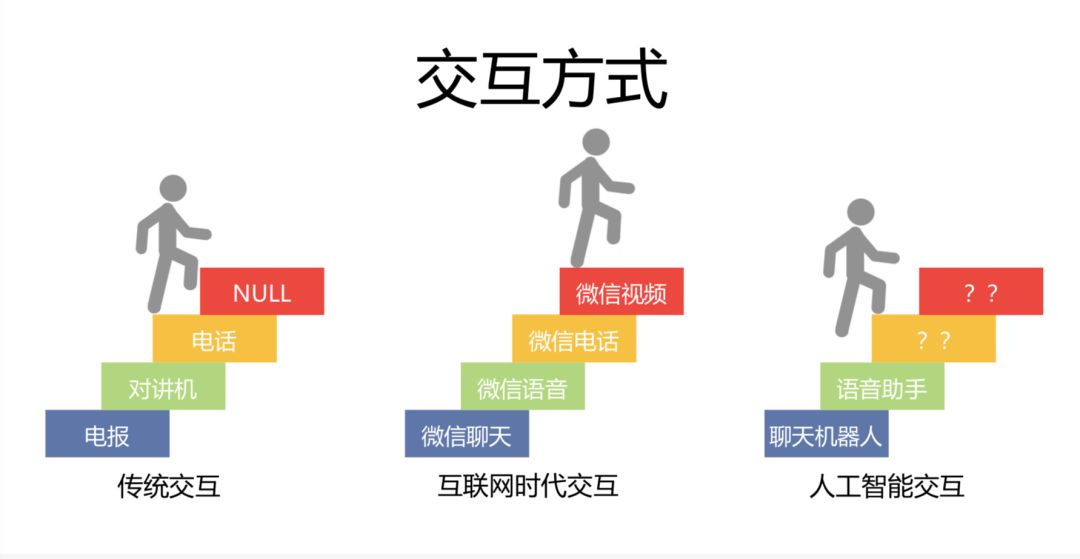
(一)人類交互方式的發展歷程
1、傳統交互。人與人之間最自然的交互方式就是面對面地進行溝通,這樣效率最高的。但是有時候不能實現面對面的交互,於是人們發明了各種工具,比如說傳遞文字的電報、飛鴿傳書等。但是有時文字不足以表達人類的情感,比如與女朋友吵架了,女朋友說的“我沒事”,你很難分辨她到底有沒有事。當通過文字已經不足以表達情感時,人類發明了傳遞聲音的工具,比如對講機(單信號傳輸)、電話(雙信道系統)。
2、互聯網時代交互。通過視頻與音頻的同步傳輸,如微信的聊天、語音、電話、視頻功能,已經無限接近於人與人之間的直接溝通,讓人與人的遠程交互更加便捷真實。
3、人工智能交互。對於人工智能來說,現在市場上有大量的聊天機器人可以傳遞文本,大量的語音助手可以傳遞語音。但人與人工智能的交流其實仍處在一個起步階段,人工智能能夠帶給人類的遠不止這些。
(二)小冰全雙工語音交互
一年多前,小冰團隊落地了“全雙工語音”的交互方式。下面從實例出發,來了解一下全雙工語音與傳統語音交互的區別。
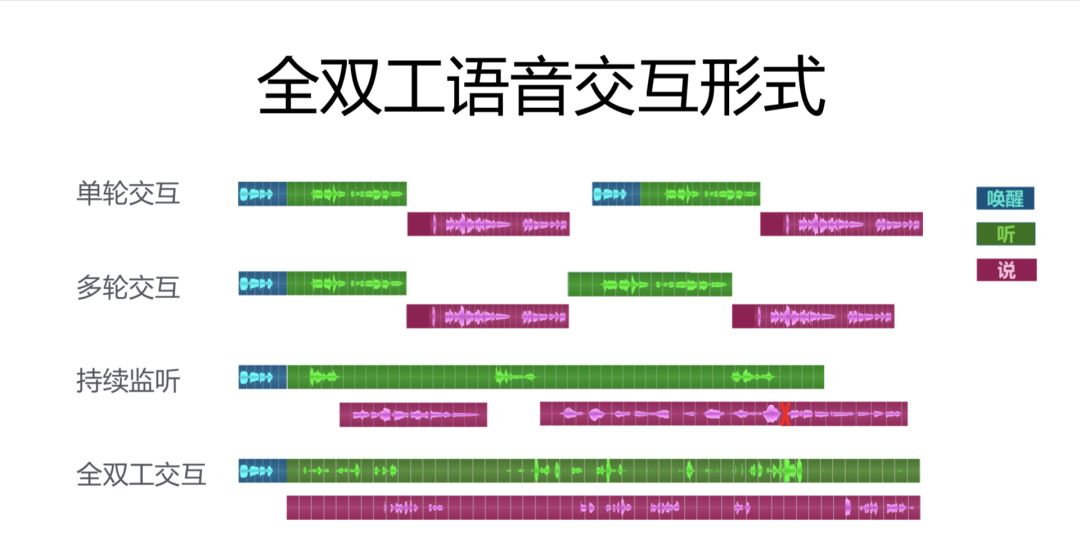
目前市場上的人工智能語音助手大概有以下幾種交互方式:
- 單輪交互。拿 Siri 做例子。你跟 Siri 之間的交互其實很簡單。你喚醒 Siri,說出你的訴求,後台處理,把結果播出來,下次需要處理命令的時候再重新喚醒,這樣的交互我們稱之為“單輪交互”。
- 多輪交互。有時候命令比較複雜,比如你想設個鬧鐘,Siri 在後台處理之後就會反問你“你想設幾點的鬧鐘?”你回答之後它會再在後台進行處理,這種連續的單輪交互形式我們稱之為“多輪交互”。
- 持續監聽。科大訊飛和京東合作的一款京東音箱中,有一個隱藏的菜單,裡邊有一種叫做“AI/UI”的模式,打開之後可以進入一種持續監聽的模式,之後如果你一旦喚醒京東音箱,它就會把麥克風一直打開,你就可以一直說,然後它針對你每一句話分別作出一個響應。但是,這個響應其實是原子操作,也就是說如果前一個響應非常長,還沒有說完的時候第二個響應就出來了,它會自動停掉第一個響應,然後播後邊一句話。 這樣就會造成一個斷斷續續的用戶體驗。這種用戶體驗非常差,甚至還不如單輪交互好。因此京東把這個功能一直隱藏,沒有大面積發布出來。
- 全雙工語音交互。相比之下,小冰的全雙工語音交互可以簡單地理解為“邊聽邊說”。用戶跟小冰交互的時候,用戶可以一直說,用戶也可以一直聽,用戶也可以打斷小冰,小冰甚至在一些特殊的情況下也可以打斷用戶。因為有了“情商”的加持,它可以做到許多前面的交互做不到的事情。
除此之外,它還有兩個特點:第一個特點就是一次喚醒,連續交互。
小冰“Yeelinght 盒子”其實是一個雙 AI 的交互機制。目前市場上大部分的“盒子”,每次交互的時候都要再次喚醒,這樣就顯得很不自然。很多媒體來給小冰進行評測,中間出現了一個非常有意思的一個現象,那就是如果評測的人先測了小冰,習慣了小冰的全雙工語音交互之後,再去測其他同學,那麼就會頻繁地忘記說喚醒詞。所以,小冰只需要一次喚醒,就可以持續與用戶進行交互,順應了人類的語言交互習慣,大大提升了用戶體驗。
第二個特點就是面向對話全程的能力。
以情商為基礎,小冰能夠控制整個對話全程,去改變對話的走向。假設我們在最開始討論《侏羅紀公園》,可能下面我們會討論電影的主角、電影的劇情,卻不會再在對話中出現電影的名字。所以這時候,全雙工語音交互就變得非常必要,因為它能控制整個對話的全程。
說實在話,全雙工語音交互的實現難度會更大,但是它的天花板會更高,因為它能完成其他交互形式完不成的任務,因此未來勢必會取代其他形式,成為一種新的主流形式。
大概在半年前,谷歌也發布了它的基於全雙工的一款產品,就是它的音箱,但是它其實是一個基於特定域的聊天,也就是說它在打電話訂餐等領域做得非常好,但是小冰是一個基於開放域的聊天,我們更加註重於情商,注重於對話本身。
小冰全雙工語音用到的技術:
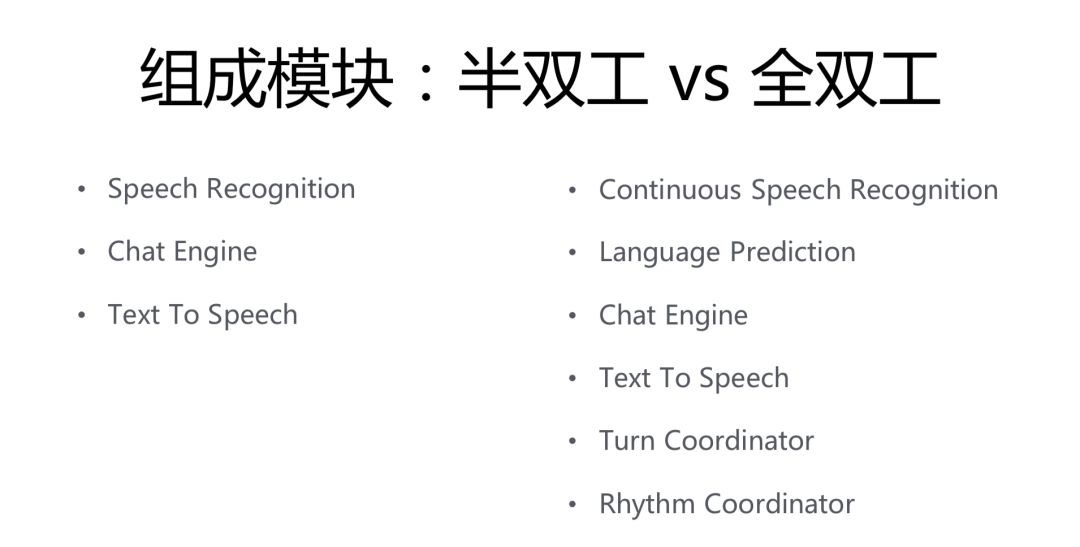
先來看一下小冰與其他語音助手的對比。
無論是單輪交互、多輪交互,還是持續監聽的交互方式,其實都是一種半雙工的語音交互。不管它內部是怎麼實現的,都逃不開這三個模塊:speech recognition(語音識別)、chat engine(把文字的輸入轉換成文字的輸出 / 或者執行命令)、text to speech(文字輸出轉換成語音)。這三個模塊是串行實行的。
而小冰的全雙工語音交互,其實在這三個模塊的基礎上,又增加了三個模塊:language prediction(語言預測)、turn coordinator(單輪協調器)、rhythm coordinator(節奏協調器)。並且,我們將第一個模塊改為了 continuous speech recognition(持續流的語音識別)。
下面通過一個圖來說明一下小冰不同模塊之間是怎麼協作的。
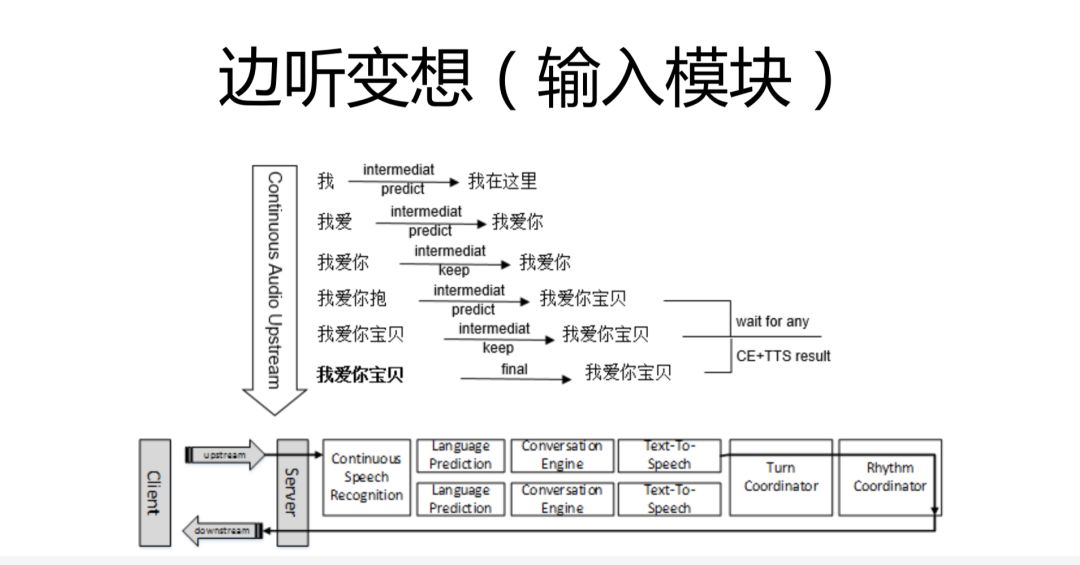
它並不是串行實施的。小冰在接到用戶的任務之後,第一個模塊就是 CSR(語音識別模塊)。每當用戶說出一個字,我們都會產生一個信號;用戶每說完一句話,我們再產生一個 Final 信號。之後,小冰會并行地開一個線程,去做後面的這些事情:先進行語言預測,根據用戶上下文和語言習慣,來預測出用戶下一步要說什麼;然後再進行後面的 conversation engine 和 TTS。
舉個例子,比如用戶想說“我愛你寶貝”,當用戶說到“寶”這個字的時候,儘管 SR 的識別是錯誤的,但是根據用戶使用習慣和上下文,小冰就可以預測出“我愛你寶貝”,那麼它就會把預測結果丟到 conversation engine 和 TTS 中去產生一个中間結果,當 Final 信號產生的時候,系統發現用戶確實要說“我愛你寶貝”,那麼小冰會把之前所有預測正確的結果,快速反饋給用戶,這就是我們的單輪協調器所做的事情。
根據經驗,這個預測外加提前返回的過程,可以提高半秒到一秒的響應時間。不要小看這半秒到一秒,舉個例子,在八九十年代人類通過衛星電話來打越洋電話,交互過程中會有幾百毫秒的延時,這樣節奏就會非常的亂。同理,半秒到一秒,可以很大程度上改善用戶體驗。
除此之外,單輪協調器還做了一件事情。那就是,如果指令回復較慢時,我們會先墊一句話,這樣就能避免用戶的重複操作,提升了用戶體驗。
比如說,因為小冰連入了米家的 IoT 環境,用戶說開燈時,它就會給用戶 IoT 平台發送一個開燈指令,緊接着我們會去輪巡這個指令的完成情況,整個過程大概需要 2 秒左右的時間。這個時候,如果機器沒有反應,用戶就會認為它沒有收到指令,然後就會再次下達指令,從而造成了一個比較混亂的局面。所以這時候,小冰就做了一件事情,它從接到指令到任務完成之前,會先墊一句話,比如“好的”。這樣,用戶就知道小冰已經接到了指令。
單輪的協調器之後,就是節奏協調器。節奏協調器之中存着兩個 buffer。第一個 buffer 存着當前正在播的這句話。另外還有一個 cursor 來指向這句話正在播到哪兒。另外它還有一個 candidates queue,來存這句話說什麼、下句話說什麼。當前這句話播完后,它就會從這裏拿出下一句話來接着播。
然後,每當有信號返回,它都會給這些結果打一些 tag。這些 tag 主要有幾個維度:
第一個維度是:與上一輪輸出之間的關係。比如,正在進行這一輪對話時,小冰收到了“關燈結束”的反饋,因為這個反饋結果非常重要,它就會給這一輪打上一個“interrupt”的標籤,然後來播下一輪。反過來,如果上一輪結果不重要,它可能就會扔掉這個新的結果。另外,conditional queue 會判斷當前用戶這句話播到哪兒了。可能上一句話非常長,還有 1 秒就馬上播完了,那麼它的下一個結果很可能就 queue 住。如果上一個結果還有很多沒播完,下一個結果又不重要,那麼下一個結果很可能就被直接扔掉。
第二個維度是:當前產生的這個結果與用戶正在說的話之間的關係。人工智能都是基於用戶本位的,如果返回的結果與用戶正在說的內容關係不大,我們一般就會直接把結果丟掉;但如果結果很重要,我們就可以打斷用戶,執行“interrupt”等模塊命令。

基於節奏協調器,小冰還做出了遞歸回復、主動回復等其他的一些行為。
比如小冰有一個 Feature 叫 FM,它與一般的 FM 大致相同,但在節目生成環節上採用的是遞歸回復。也就是說,用戶發出任務后,只給用戶生成一個節目,等節目快播完的時候,再去返回到 conversation engine,生成下一個節目,然後再播,這樣就防止了突發新聞、任務變更等帶來的影響。
對於尬聊問題,小冰會有一種主動回復的交互形式。交互過程中,如果用戶 5 秒鐘還沒有說話,後台 classifier 就會判斷用戶是不是不想說了,如果判斷為用戶是真不說了,它就會結束交互;如果判斷為用戶還在等小冰的回復,但它其實已經回答完畢了,也就是出現“冷場”情況時,classifier 就會再往 conversation engine 中發一個請求,根據用戶使用習慣,主動拋個話題給用戶,以期實現順暢交互。
全雙工語音與半雙工語音的不同在於,它是一個多模態的輸入,它不僅僅是輸入文字的東西,還有一些對於聲音場景的理解等其他內容,比如小冰的一些其他的 Feature,像語音身份識別、語音聲紋識別、背景噪音識別、是否在對小冰說話等。

全雙工語音的未來發展方向,主要有以下三個維度:
- 從場景來說,小冰最開始上線是基於微信的一對一場景,屬於個人場景;Yeelinght 盒子主要存在於家庭場景;同時我們也有喵駕等車載場景的智能設備;而在未來,我們會把場景越做越大,以至於在公共空間場景中發揮作用。
- 從交互形式來看,目前大多數人工智能都是一對一的交互形式,我們現在可以進行一對多的交互,未來我們會往多人同時交互、多設備聯動交互方向發展。
- 與實時視覺感官的結合:相當於語音與圖像的結合,這是小冰最重要的一個發展方向。

(三)實時視覺感官交互
首先,着重介紹一下實時視覺感官。
在全雙工語音交互基礎上,小冰團隊還進行了一系列視覺交互形式的探索。因為對於人工智能來說,語音和視覺這兩種感官結合之後,最終還是會落入語音感官。但如果直接做語音和視覺感官的結合的話,視覺感官不可能得到一個很好的修鍊。所以,小冰團隊就單獨進行了提升視覺感官體驗的探索,這就是小冰的實時視覺感官交互。
視覺感官交互主要是一種基於電視和攝像頭的部署方式。簡單來講,我們有一台裝了攝像頭的電視,那麼攝像頭會拍到電視前面的內容(輸入),然後把拍到的東西再輸出為電視畫面(視覺流輸出)。它還可以說話,但是只能它跟用戶說,不能用戶跟他說(音頻流輸出)。
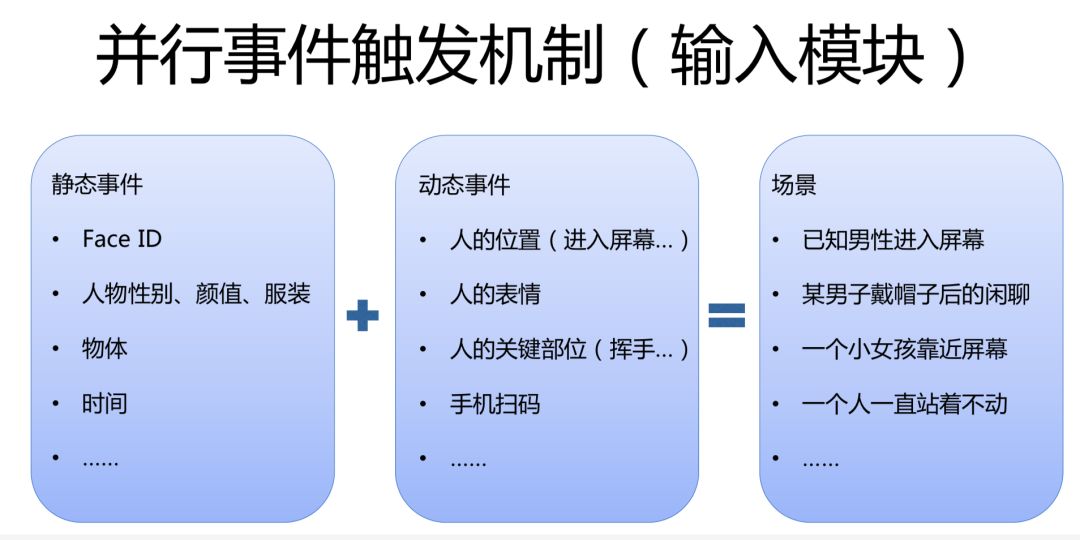
下面從技術角度說明一下,小冰是如何完成一個 DEMO 的。
其實,實時視覺感官和全雙工語音感官是類似的,所不一樣的是,實時視覺感官是分層輸入的,最底層是唯一輸入的視頻流,再往上一層跟大多數的視頻處理方式一樣,會切成若干幀,比如每 15 毫秒會切一幀。再往上會根據每一幀來提取一些信息。比如說我們可以看到一幀圖片中有一個人,我們根據他的 Face ID 來識別這個人到底是誰,識別他的顏值等等,這叫靜態事件。
基於多幀的信息,小冰就能提取出動態事件。比如前面一幀沒有人,後面一幀出現了一個較小的人,我們就會認為一個人從遠處走了過來。
把靜態事件和動態事件組合起來,作為 conversation engine 的輸入,然後產生輸出,拼湊出產生的一些場景。比如我們可以分析出“已知男性進入屏幕”等場景信息。
視覺感官與語音感官所不一樣的是,全雙工語音感官同一時刻只能有一個輸入,但視覺感官卻可以在同一時刻輸入不同的信息。如:畫面中有一個人在跳繩,另兩個人在打架,小冰可以把每個人都框出一些信息,作為視頻流的輸入,同時產生輸出。而我們的輸出也很簡單,需要注意的是,視頻流可以併發輸出,但音頻流的輸出則只有一個。
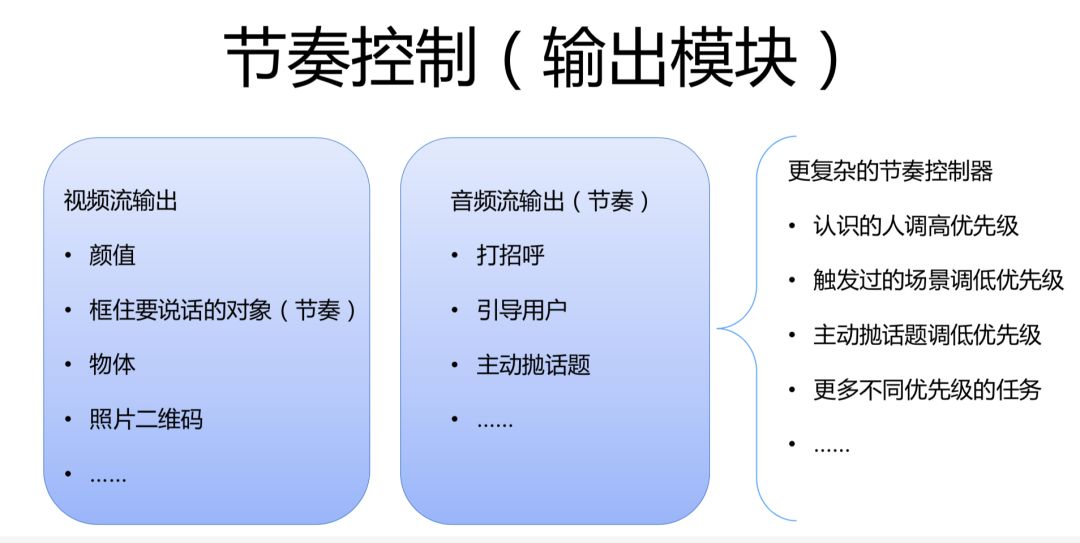
實時視覺感官的未來發展方向:
一方面,小冰目前的產品線主要是向大屏商業化和小型設備用戶化方向發展,比如與寶馬 4S 店合作,實現了 ToB 的落地。另一方面,在基礎能力上,我們還要提高對更多物體的識別能力,判斷物體和人物之間的關係,以期應用於更多的場景,實現更大的功能。
(四)兩種感官的進一步結合
小冰在全雙工語音交互與實時視覺感官相結合方面,仍處於一個非常初級的階段。從交流方式上來看,小冰大部分的場景還是只基於聽覺的;但是有一些場景,它可以通過視覺場景來彌補聽覺,比如你問小冰“我漂亮嗎?”小冰可能會判斷出你是負責開發我的,所以我說你特別好看。
這裡有一個特殊的場景,就是說話人識別。我們基於 Voice ID 其實是一個比較初級的階段,識別準確率不高,但是人臉識別是一個準確率特別高、非常成熟的一個技術。因此我們可以用那個人的人臉,以及看他是不是張嘴,來判斷出到底是誰在說話。
未來的小冰,甚至可以只靠視覺來進行交互。比如,用戶可以憑藉肢體語言來直接喚醒小冰。當用戶直接看電視時,小冰就可能跟他進行交互,問他我要打開電視嗎?
暢想一下,如果大家某天開車去了郊外,坐在你身邊的其實是微軟小冰,你們用着全雙工語音在進行溝通,小冰還在某些領域有着自己的看法,這個時候她突然跟你說,“哎呀,這裏好漂亮啊,咱們下次再來吧!”這其實是我們一直期盼的一個場景。相信隨着 5G 時代的到來,這種場景的到來已經不遠了。
作者介紹
李想,Microsoft Principal Software Manager 本科碩士分別就讀於復旦大學、中國科學院計算技術研究所。先後工作於 Yahoo 全球技術研發中心和微軟亞洲互聯網工程院。 目前在小冰部門,負責小冰系統架構的設計與實現,和重點平台的對接。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【精選推薦文章】
帶您來了解什麼是 USB CONNECTOR ?
為什麼 USB CONNECTOR 是電子產業重要的元件?
又掌控什麼技術要點? 帶您認識其相關發展及效能