預訓練語言模型整理(ELMo/GPT/BERT…)
目錄
簡介
2018年ELMo/GPT/BERT的相繼提出,不斷刷新了各大NLP任務排行榜,自此,NLP終於找到了一種方法,可以像計算機視覺那樣進行遷移學習,被譽為NLP新時代的開端。
與計算機視覺領域預訓練模型不同的是,其通過採用自監督學習的方法,將大量的無監督文本送入到模型中進行學習,即可得到通用的預訓練模型,而NLP領域中無監督文本數據要多少有多少,2019年發布的後續研究工作(GPT2、Roberta、T5等)表明,採用更大的數據、更強大的煉丹爐可以不斷提高模型性能表現,至少目前看來還沒有達到上限。同時,如何縮減模型參數也成為了另一個研究熱點,並有相應的論文在今年發表(ALBERT、ELECTRA)。這一類工作為NLP研發者趟通並指明了一條光明大道:就是通過自監督學習,把大量非監督的文本充分利用起來,並將其中的語言知識編碼,對各種下游NLP任務產生巨大的积極作用。
為何預訓練語言模型能夠達到如此好的效果?主要有如下幾點:
- word2vec等詞向量模型訓練出來的都是靜態的詞向量,即同一個詞,在任何的上下文當中,其向量表徵是相同的,顯然,這樣的一種詞向量是無法體現一個詞在不同語境中的不同含義的。
- 我們採用預訓練模型來代替詞向量的關鍵在於,其能夠更具上下文的不同,對上下文中的詞提取符合其語境的詞表徵,該詞表徵向量為一個動態向量,即不同上下文輸入預訓練模型后,同一個詞的詞表徵向量在兩個上下文中的詞表徵是不同的。
本文將對一下幾個模型進行簡單的總結,主要關注點在於各大模型的主要結構,預訓練任務,以及創新點: - ELMo
- GPT
- BERT
- BERT-wwm
- ERNIE_1.0
- XLNET
- ERNIE_2.0
- RoBERTa
- (ALBERT/ELECTRA)
- …
預訓練任務簡介
總的來說,預訓練模型包括兩大類:自回歸語言模型與自編碼語言模型
自回歸語言模型
通過給定文本的上文,對當前字進行預測,訓練過程要求對數似然函數最大化,即:
\[max_{\theta} \ logp_{\theta}(x) = \sum_{t=1}^{T}log \ p_{\theta}(x_t|x_{<t})\]
代表模型:ELMo/GPT1.0/GPT2.0/XLNet
優點:該模型對文本序列聯合概率的密度估計進行建模,使得該模型更適用於一些生成類的NLP任務,因為這些任務在生成內容的時候就是從左到右的,這和自回歸的模式天然匹配。
缺點:聯合概率是按照文本序列從左至右進行計算的,因此無法得到包含上下文信息的雙向特徵表徵;
自編碼語言模型
BERT系列的模型為自編碼語言模型,其通過隨機mask掉一些單詞,在訓練過程中根據上下文對這些單詞進行預測,使預測概率最大化,即
\[max_{\theta} \ logp_{\theta}(\bar{x}|\hat{x}) \approx \sum_{t=1}^{T}log \ m_tp_{\theta}(x_t|\hat{x}) = \sum_{t=1}^{T}log \ m_tlog\frac{exp(H_{\theta}(\hat{x})_t^Te(x_t))}{\sum_{x’}exp(H_{\theta}(\hat{x})_t^Te(x’))}\]
其本質為去噪自編碼模型,加入的 [MASK] 即為噪聲,模型對 [MASK] 進行預測即為去噪。
優點:能夠利用上下文信息得到雙向特徵表示
缺點:其引入了獨立性假設,即每個 [MASK] 之間是相互獨立的,這使得該模型是對語言模型的聯合概率的有偏估計;另外,由於預訓練中 [MASK] 的存在,使得模型預訓練階段的數據與微調階段的不匹配,使其難以直接用於生成任務。
預訓練模型的簡介與對比
ELMo
原文鏈接:
ELMo為一個典型的自回歸預訓練模型,其包括兩個獨立的單向LSTM實現的單向語言模型進行自回歸預訓練,不使用雙向的LSTM進行編碼的原因正是因為在預訓練任務中,雙向模型將提前看到上下文表徵而對預測結果造成影響。因此,ELMo在本質上還是屬於一個單向的語言模型,因為其只在一個方向上進行編碼錶征,只是將其拼接了而已
細節
- 引入雙向語言模型,其實是2個單向語言模型(前向和後向)的集成,這樣做的原因在上一節已經解釋過了,用共享詞向量來進行預訓練;
- 通過保存預訓練好的2層biLSTM,提取每層的詞表徵用於下游任務;
ELMo的下游使用
-
對於每一個字符,其每一層的ELMo表徵均為輸入詞向量與該層的雙向編碼錶征拼接而成,即:
\[R_k = \{x^{LM}_k, \overrightarrow{h}^{LM}_{k,j}, \overleftarrow{h}^{LM}_{k,j} | j = 1, …, L\} = \{h^{LM}_{k,j}|j = 0, …, L\}\] -
對於下游任務而言,我們需要把所有層的ELMo表徵整合為一個單獨的向量,最簡單的方式是只用最上層的表徵,而更一般的,我們採用對所有層的ELMo表徵採取加權和的方式進行處理,即:
\[ELMo^{task}_k = E(R_k; \theta ^{task}) = \gamma ^{task}\sum_{j=0}^L s^{task}h^{LM}_{k,j}\]
其中\(s^{task}\)可以作為學習參數,為一個歸一化的權重因子,用於表示每一層的詞向量在整體的重要性。\(\gamma ^{task}\)為縮放參數,允許具體的task模型去放縮 ELMo 的大小,因為ELMo的表徵分佈與具體任務的表徵分佈不一定是一樣的,可以將其作為一個輔助特徵參數。
- 得到ELMo表徵之後,則需要將其用於下游任務中去,注意,ELMo的微調過程中,並不是嚴格意義上的微調,預訓練模型部分通常是固定的,不參与到後續訓練當中。具體的,有以下幾種操作方法:
- 方法一:直接將ELMo表徵與詞向量拼接,輸入到下游任務當中去;
- 方法二:直接將ELMo表徵與下游模型的輸出層拼接
- 另外,還可以在ELMo模型中加入dropout, 以及採用 L2 loss的方法來提升模型。
GPT/GPT2
GPT:
GPT2:
GPT
GPT是“Generative Pre-Training”的簡稱,從名字上就可以看出其是一個生成式的預訓練模型,即與ELMo類似,是一個自回歸語言模型。與ELMo不同的是,其採用多層Transformer Decoder作為特徵抽取器,多項研究也表明,Transformer的特徵抽取能力是強於LSTM的。
細節
- 由於GPT仍然是一個生成式的語言模型,因此需要採用Mask Multi-Head Attention的方式來避免預測當前詞的時候會看見之後的詞,因此將其稱為單向Transformer,這也是首次將Transformer應用於預訓練模型,預測的方式就是將position-wise的前向反饋網絡的輸出直接送入分類器進行預測
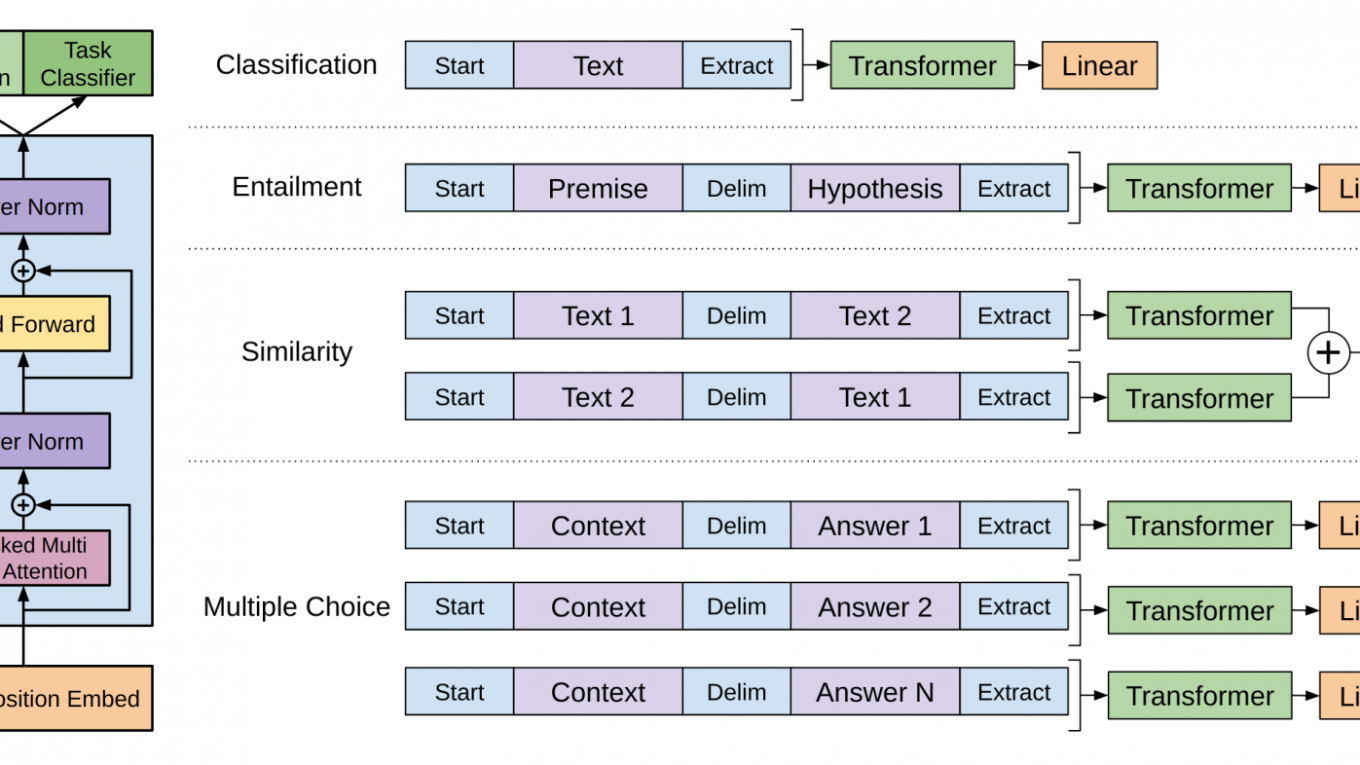
- 此外整個GPT的訓練包括預訓練和微調兩個部分,或者說,對於具體的下游任務,其模型結構也必須採用與預訓練相同的結構,區別僅在於數據需要進行不同的處理
微調
對於帶有標籤\(y\)的監督數據\([x_1, …, x_m]\),我們直接將其輸入到已經完成預訓練的模型中,然後利用最後一個位置的輸出對標籤進行預測,即
\[P(y|x^1, …, x^m) = softmax(h_l^mW_y)\]
其中,\(W_y\)為分類器的參數,\(h_l^m\)為最後一層最後一個位置的輸出。則最大化優化目標即為:
\[ L_2(C) = \sum_{(x, y)}^{T}log \ P(y|x^1, …, x^m)\]
具體的,對於不同的微調任務,我們需要對數據進行如下處理:
GPT2
GPT2 與 GPT 的大致模型框架和預訓練目標是一致的,而區別主要在於以下幾個方面:
- 其使用了更大的模型
- 使用了數量更大、質量更高、涵蓋範圍更廣的預訓練數據
- 採用了無監督多任務聯合訓練的方式,即對於輸入樣本,給予一個該樣本所屬的類別作為引導字符串,這使得該模型能夠同時對多項任務進行聯合訓練,並增強模型的泛化能力
其他的就不深究了
優缺點
BERT
原文鏈接:
BERT 的特徵抽取結構為雙向的 Transformer,簡單來說,就直接套用了 Attention is all you need 中的 Transformer Encoder Block 結構,雖然相比於GPT,僅僅是從單向的變為雙向的,但這也意味着 BERT 無法適用於自回歸語言模型的預訓練方式,因此,BERT提出了兩種預訓練任務來對其模型進行預訓練。
BERT的預訓練
Task 1: MLM
由於BERT需要通過上下文信息,來預測中心詞的信息,同時又不希望模型提前看見中心詞的信息,因此提出了一種 Masked Language Model 的預訓練方式,即隨機從輸入預料上 mask 掉一些單詞,然後通過的上下文預測該單詞,類似於一個完形填空任務。
在預訓練任務中,15%的 Word Piece 會被mask,這15%的 Word Piece 中,80%的時候會直接替換為 [Mask] ,10%的時候將其替換為其它任意單詞,10%的時候會保留原始Token
- 沒有100%mask的原因
- 如果句子中的某個Token100%都會被mask掉,那麼在fine-tuning的時候模型就會有一些沒有見過的單詞
- 加入10%隨機token的原因
- Transformer要保持對每個輸入token的分佈式表徵,否則模型就會記住這個[mask]是token ’hairy‘
- 另外編碼器不知道哪些詞需要預測的,哪些詞是錯誤的,因此被迫需要學習每一個token的表示向量
- 另外,每個batchsize只有15%的單詞被mask的原因,是因為性能開銷的問題,雙向編碼器比單項編碼器訓練要更慢
Task 2: NSP
僅僅一個MLM任務是不足以讓 BERT 解決閱讀理解等句子關係判斷任務的,因此添加了額外的一個預訓練任務,即 Next Sequence Prediction。
具體任務即為一個句子關係判斷任務,即判斷句子B是否是句子A的下文,如果是的話輸出’IsNext‘,否則輸出’NotNext‘。
訓練數據的生成方式是從平行語料中隨機抽取的連續兩句話,其中50%保留抽取的兩句話,它們符合IsNext關係,另外50%的第二句話是隨機從預料中提取的,它們的關係是NotNext的。這個關係保存在圖4中的[CLS]符號中
輸入表徵
BERT的輸入表徵由三種Embedding求和而成:
- Token Embeddings:即傳統的詞向量層,每個輸入樣本的首字符需要設置為[CLS],可以用於之后的分類任務,若有兩個不同的句子,需要用[SEP]分隔,且最後一個字符需要用[SEP]表示終止
- Segment Embeddings:為\([0, 1]\)序列,用來在NSP任務中區別兩個句子,便於做句子關係判斷任務
- Position Embeddings:與Transformer中的位置向量不同,BERT中的位置向量是直接訓練出來的
Fine-tunninng
對於不同的下游任務,我們僅需要對BERT不同位置的輸出進行處理即可,或者直接將BERT不同位置的輸出直接輸入到下游模型當中。具體的如下所示:
- 對於情感分析等單句分類任務,可以直接輸入單個句子(不需要[SEP]分隔雙句),將[CLS]的輸出直接輸入到分類器進行分類
- 對於句子對任務(句子關係判斷任務),需要用[SEP]分隔兩個句子輸入到模型中,然後同樣僅須將[CLS]的輸出送到分類器進行分類
- 對於問答任務,將問題與答案拼接輸入到BERT模型中,然後將答案位置的輸出向量進行二分類並在句子方向上進行softmax(只需預測開始和結束位置即可)
- 對於命名實體識別任務,對每個位置的輸出進行分類即可,如果將每個位置的輸出作為特徵輸入到CRF將取得更好的效果。
缺點
- BERT的預訓練任務MLM使得能夠藉助上下文對序列進行編碼,但同時也使得其預訓練過程與中的數據與微調的數據不匹配,難以適應生成式任務
- 另外,BERT沒有考慮預測[MASK]之間的相關性,是對語言模型聯合概率的有偏估計
- 由於最大輸入長度的限制,適合句子和段落級別的任務,不適用於文檔級別的任務(如長文本分類);
- 適合處理自然語義理解類任務(NLU),而不適合自然語言生成類任務(NLG)
ELMo/GPT/BERT對比,其優缺點
ELMo/GPT/BERT 均為在2018年提出的三個模型,且性能是依次提高的,這裏將其放在一起對比,來看看這三者之間的主要區別有哪些
- ELMo 的特徵提取器為LSTM,特徵抽取能力明顯較Transformer更弱,且并行能力較差
- ELMo/GPT 均為單向語言模型,即自回歸語言模型,天生適合用於處理生成式任務,但這種特性也決定了無法提取上下文信息用於序列編碼
- BERT採用雙向Transformer作為特徵抽取結構,能夠有效提取上下文信息用於序列編碼
BERT-wwm
原文鏈接:
Github鏈接:
Whole Word Masking (wwm),暫翻譯為全詞Mask或整詞Mask,是哈工大訊飛聯合實驗室提出的BERT中文預訓練模型的升級版本,主要更改了原預訓練階段的訓練樣本生成策略。 簡單來說,原有基於WordPiece的分詞方式會把一個完整的詞切分成若干個子詞,在生成訓練樣本時,這些被分開的子詞會隨機被mask。
在全詞Mask中,如果一個完整的詞的部分WordPiece子詞被mask,則同屬該詞的其他部分也會被mask,即全詞Mask。這樣的做法強制模型預測整個的詞,而不是詞的一部分,即對同一個詞不同字符的預測將使得其具有相同的上下文,這將加強同一個詞不同字符之間的相關性,或者說引入了先驗知識,使得BERT的獨立性假設在同一個詞的預測上被打破,但又保證了不同的詞之間的獨立性。
作者將全詞Mask的方法應用在了中文中,使用了中文維基百科(包括簡體和繁體)進行訓練,並且使用了哈工大LTP作為分詞工具,即對組成同一個詞的漢字全部進行Mask。這樣一個簡單的改進,使得同樣規模的模型,在中文數據上的表現獲得了全方位的提升
RoBERTa
從模型結構上看,RoBERTa基本沒有什麼太大創新,最主要的區別有如下幾點:
- 移除了NSP這個預訓練任務,效果變得更好
-
動態改變mask策略,把數據複製10份,然後統一進行隨機mask;
-
其他的區別就在於學習率/數據量/batch_size 等
ERNIE(艾尼) 1.0
作者認為BERT在中文文本中的MLM預訓練模型很容易使得模型提取到字搭配這種低層次的語義信息,而對於短語以及實體層次的語義信息抽取能力是較弱的。因此將外部知識引入大規模預訓練語言模型中,提高在知識驅動任務上的性能。具體有如下三個層次的預訓練任務:
- Basic-Level Masking: 跟bert一樣對單字進行mask,很難學習到高層次的語義信息;
- Phrase-Level Masking: 輸入仍然是單字級別的,mask連續短語;
- Entity-Level Masking: 首先進行實體識別,然後將識別出的實體進行mask。
ERNIE 2.0
ERNIE 2.0相比於 1.0 來說,主要的改進在於採取 Multi-task learning(多任務同時學習,同時學習的任務數量逐漸增多)以及 Continue-Learning(不同任務組合輪番學習)的機制。其訓練任務包括了三個級別的任務:
- 詞級別:
- Knowledge Masking(短語Masking)
- Capitalization Prediction(大寫預測)
- Token-Document Relation Prediction(詞是否會出現在文檔其他地方)
- 結構級別
- Sentence Reordering(句子排序分類)
- Sentence Distance(句子距離分類)
- 語義級別:
- Discourse Relation(句子語義關係)
- IR Relevance(句子檢索相關性)
XLNet
XLNet針對自回歸語言模型單向編碼以及BERT類自編碼語言模型的有偏估計的缺點,提出了一種廣義自回歸語言預訓練方法。
提出背景
- 傳統的語言模型(自回歸語言模型AR天然適合處理生成任務,但是無法對雙向上下文進行表徵;
- 而自編碼語言模型(AE)雖然可以實現雙向上下文進行表徵,但是:
- BERT系列模型引入獨立性假設,沒有考慮預測[MASK]之間的相關性;
- MLM預訓練目標的設置造成預訓練過程和生成過程不一致;
- 預訓練時的[MASK]噪聲在finetune階段不會出現,造成兩階段不匹配問題;
- XLNet提出了一種排列語言模型(PLM),它綜合了自回歸模型和自編碼模型的優點,同時避免他們的缺點
排列語言模型(Permutation Language Model,PLM)
排列語言模型的思想就是在自回歸和自編碼的方式中間額外添加一個步驟,即可將兩者完美統一起來,具體的就是希望語言模型從左往右預測下一個字符的時候,不僅要包含上文信息,同時也要能夠提取到對應字符的下文信息,且不需要引入Mask符號。即在保證位置編碼不變的情況下,將輸入序列的順序打亂,然後預測的順序還是按照原始的位置編碼順序來預測的,但是相應的上下文就是按照打亂順序的上下文來看了,這樣以來,預測對象詞的時候,可以隨機的看到上文信息和下文信息。另外,假設序列長度為\(T\),則我們如果遍歷\(T!\)種分解方法,並且模型參數是共享的,PLM就一定可以學習到預測詞的所有上下文信息。但顯然,遍歷\(T!\)種上下文計算量是十分大的,XLNet採用的是一個部分預測的方法(Partial Prediction),為了減少計算量,作者只對隨機排列后的末尾幾個詞進行預測,並使得如下期望最大化:
\[max_{\theta} \ E_{Z \sim Z_T}[\sum_{t = 1}^{T}logp_{\theta}(x_{z_t}|x_{z < t})]\]
Two-Stream Self-Attention
直接用標準的Transformer來建模PLM,會出現沒有目標(target)位置信息的問題。即在打亂順序之後,我們並不知道下一個要預測的詞是一個什麼詞,這將導致用相同上文預測不同目標的概率是相同的。
XLNet引入了雙流自注意力機制(Two-Stream Self-Attention)來解決這個問題。Two-Stream Self-Attention表明了其有兩個分離的Self-Attention信息流:
- Query Stream 就為了找到需要預測的當前詞,這個信息流的Self-Attention的Query輸入是僅包含預測詞的位置信息,而Key和Value為上下文中包含內容信息和位置信息的輸入,表明我們無法看見預測詞的內容信息,該信息是需要我們去預測的;
- Content Stream 主要為 Query Stream 提供其它詞的內容向量,其Query輸入為包含預測詞的內容信息和位置信息,Value和Key的輸入為選中上下文的位置信息和內容信息;
兩個信息流的輸出同樣又作為對應的下一層的雙信息流的輸入。而隨機排列機制實際上是在內部用Mask Attention的機制實現的。
Transformer-XL
Transformer-XL是 XLNet 的特徵抽取結構,其相比於傳統的Transformer能捕獲更長距離的單詞依賴關係。
原始的Transformer的主要缺點在於,其在語言建模中會受到固定長度上下文的限制,從而無法捕捉到更長遠的信息。
Transformer-XL採用片段級遞歸機制(segment-level recurrence mechanism)和相對位置編碼機制(relative positional encoding scheme)來對Transformer進行改進。
-
片段級遞歸機制:指的是當前時刻的隱藏信息在計算過程中,將通過循環遞歸的方式利用上一時刻較淺層的隱藏狀態,這使得每次的計算將利用更大長度的上下文信息,大大增加了捕獲長距離信息的能力。
-
相對位置編碼:Transformer本身引入了三角函數向量作為位置編碼向量。而Transformer-XL復用了上文的信息,這就導致位置編碼出現重疊,因此採用了訓練的方式得到相對位置編碼向量。
ALBERT
未完待續…
參考鏈接
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【精選推薦文章】
自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"